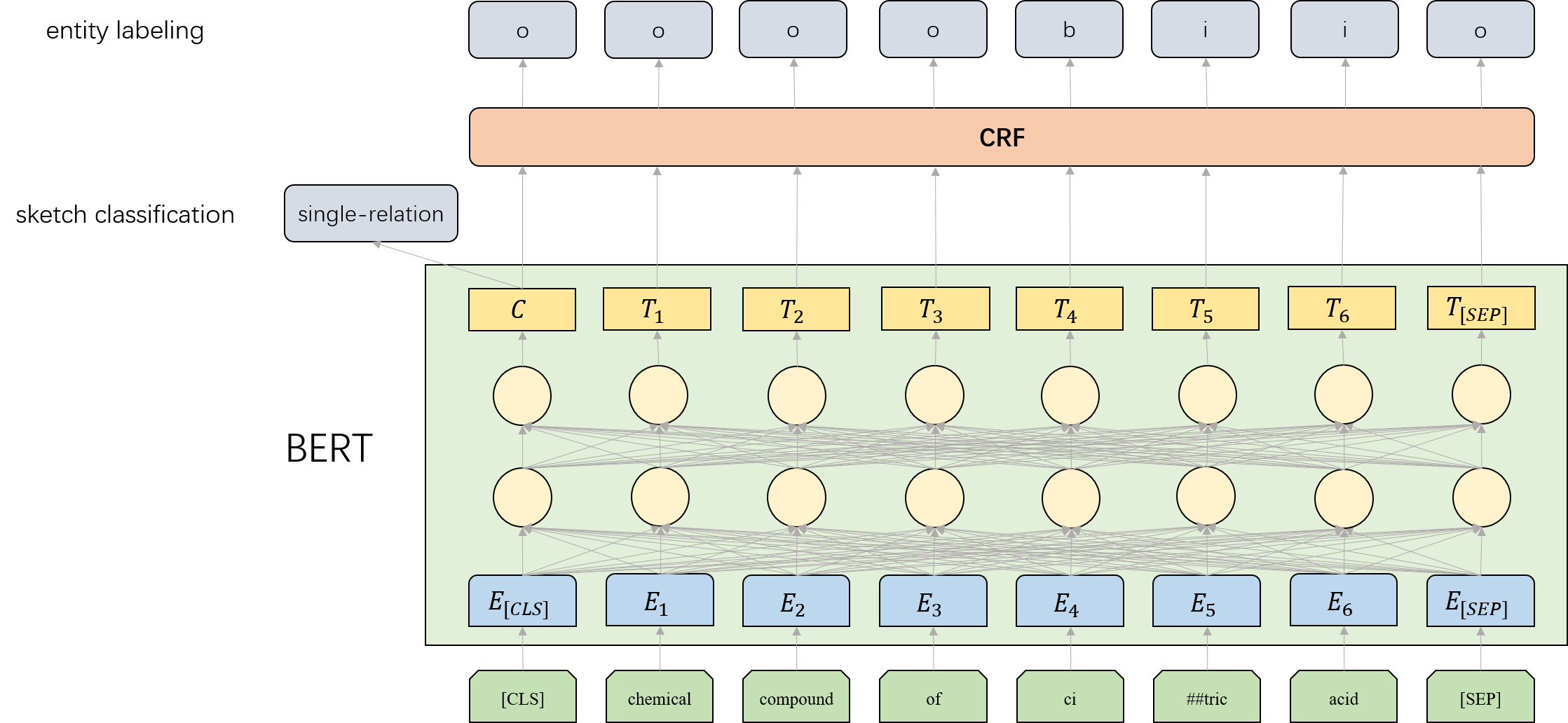
This paper presents our semantic parsing system for the evaluation task of open domain semantic parsing in NLPCC 2019. Many previous works formulate semantic parsing as a sequence-to-sequence(seq2seq) problem. Instead, we treat the task as a sketch-based problem in a coarse-to-fine(coarse2fine) fashion. The sketch is a high-level structure of the logical form exclusive of low-level details such as entities and predicates. In this way, we are able to optimize each part individually. Specifically, we decompose the process into three stages: the sketch classification determines the high-level structure while the entity labeling and the matching network fill in missing details. Moreover, we adopt the seq2seq method to evaluate logical form candidates from an overall perspective. The co-occurrence relationship between predicates and entities contribute to the reranking as well. Our submitted system achieves the exactly matching accuracy of 82.53% on full test set and 47.83% on hard test subset, which is the 3rd place in NLPCC 2019 Shared Task 2. After optimizations for parameters, network structure and sampling, the accuracy reaches 84.47% on full test set and 63.08% on hard test subset.
翻译:本文展示了用于 NLPCC 2019 的开放域域语义分析评估任务的语义解析系统。 许多先前的作品将语义解解析作为序列到序列的问题。 相反, 我们用粗略到直线( coarse2fine) 的方式将任务视为草图问题。 草图是一个逻辑形式的高层次结构, 不包括实体和上游等低层细节。 这样, 我们就能将每个部分都优化。 具体地说, 我们把过程分解为三个阶段: 素描分类决定高层次结构, 而实体标签和匹配网络则以缺失的细节填充。 此外, 我们采用后方2等方法从整体角度来评估逻辑形式的候选人。 上游和实体之间的共同关联关系也有助于重新排序。 我们提交的系统在完整测试集和47.83%的硬测试子集上实现了精确匹配的准确度, 这是 NLPCC 标签分类决定了高层次结构, 而实体标签和匹配的网络的匹配度网络标定值为 2019 深度测试参数 和精确度 优化后, 优化后, 将完成 测试 测试 度为 试定的精确度 2. 度 和精确度