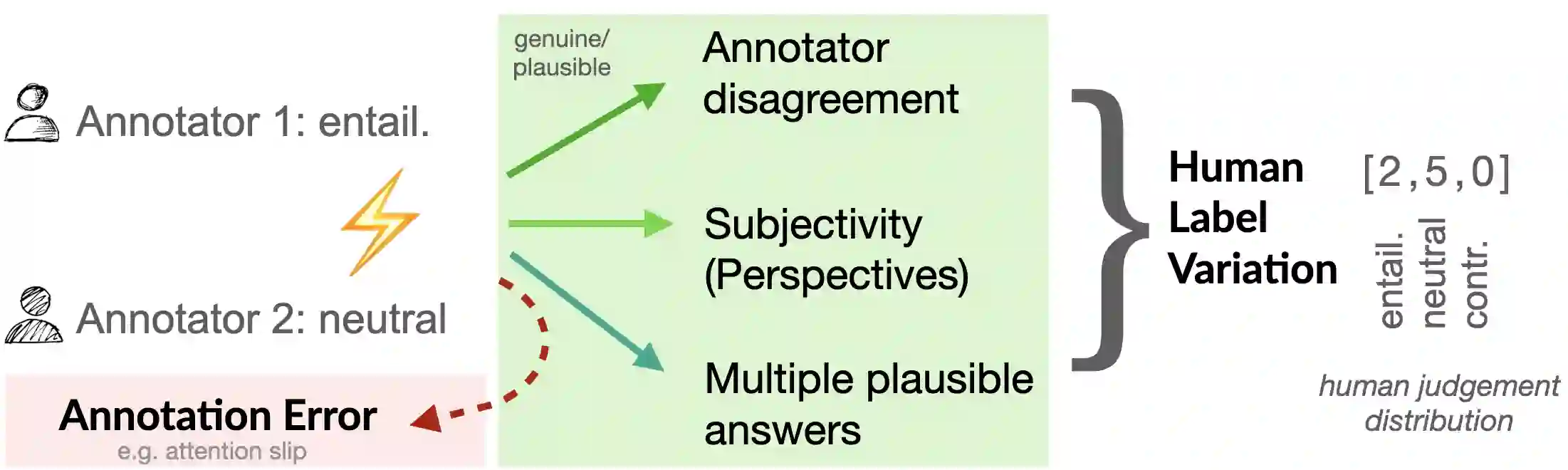
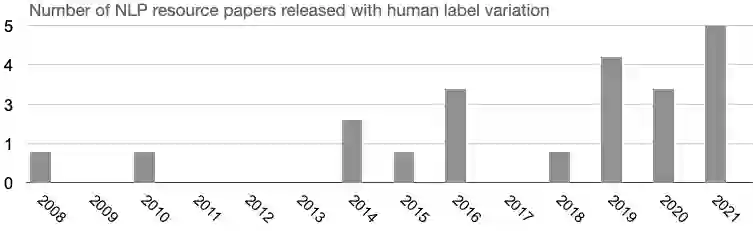
Human variation in labeling is often considered noise. Annotation projects for machine learning (ML) aim at minimizing human label variation, with the assumption to maximize data quality and in turn optimize and maximize machine learning metrics. However, this conventional practice assumes that there exists a ground truth, and neglects that there exists genuine human variation in labeling due to disagreement, subjectivity in annotation or multiple plausible answers. In this position paper, we argue that this big open problem of human label variation persists and critically needs more attention to move our field forward. This is because human label variation impacts all stages of the ML pipeline: data, modeling and evaluation. However, few works consider all of these dimensions jointly; and existing research is fragmented. We reconcile different previously proposed notions of human label variation, provide a repository of publicly-available datasets with un-aggregated labels, depict approaches proposed so far, identify gaps and suggest ways forward. As datasets are becoming increasingly available, we hope that this synthesized view on the 'problem' will lead to an open discussion on possible strategies to devise fundamentally new directions.
翻译:标签中的人类变异往往被视为噪音。 机器学习的批注项目旨在尽量减少人类标签变异,其假设是最大限度地提高数据质量,进而优化和最大限度地优化机器学习尺度。 但是,这一常规做法假定存在一个地面真理,忽视了在标签上存在真正的人类变异,原因是在批注中存在分歧、主观性或多种可信的答案。在本立场文件中,我们争辩说,人类标签变异的这一大开放问题依然存在,迫切需要更多关注推进我们的领域。这是因为人类标签变异影响ML管道的各个阶段:数据、建模和评价。然而,很少有工作能够共同考虑所有这些层面;现有研究是零散的。我们调和以前提出的人类标签变异的不同概念,提供公开可用的数据集的存放处,并配有未分类的标签,描述迄今提出的办法,找出差距并提出前进的方法。随着数据集的日益普及,我们希望关于“问题”的合成观点将导致就制定根本新方向的可能战略进行公开讨论。