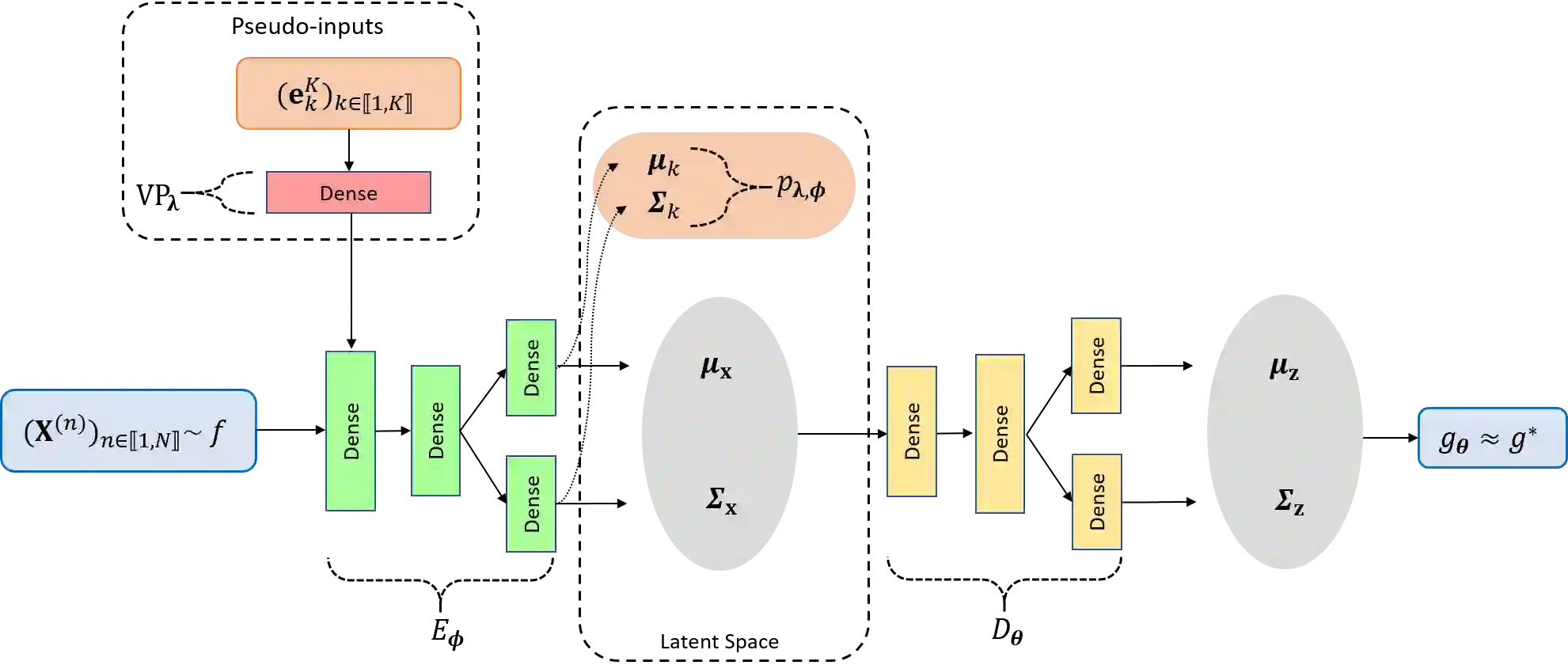
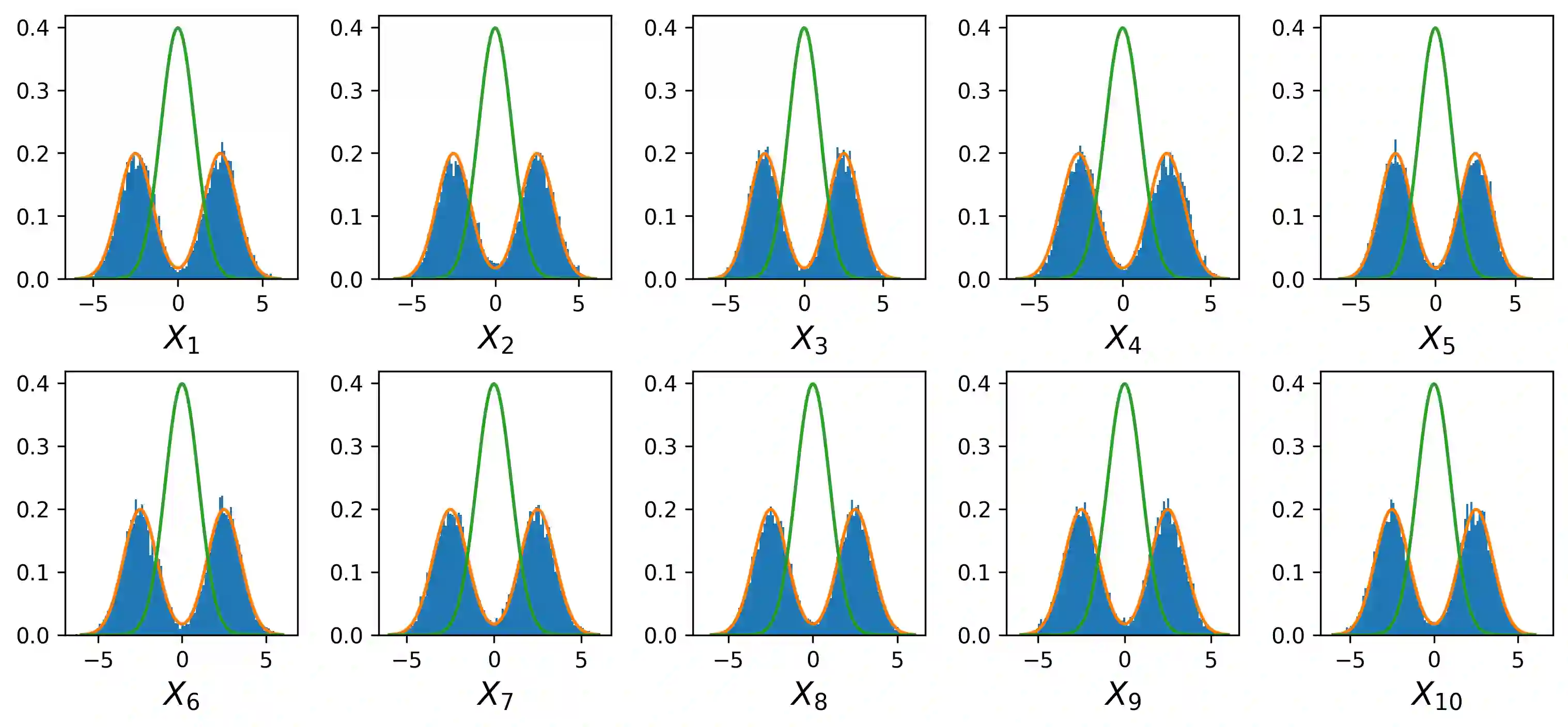
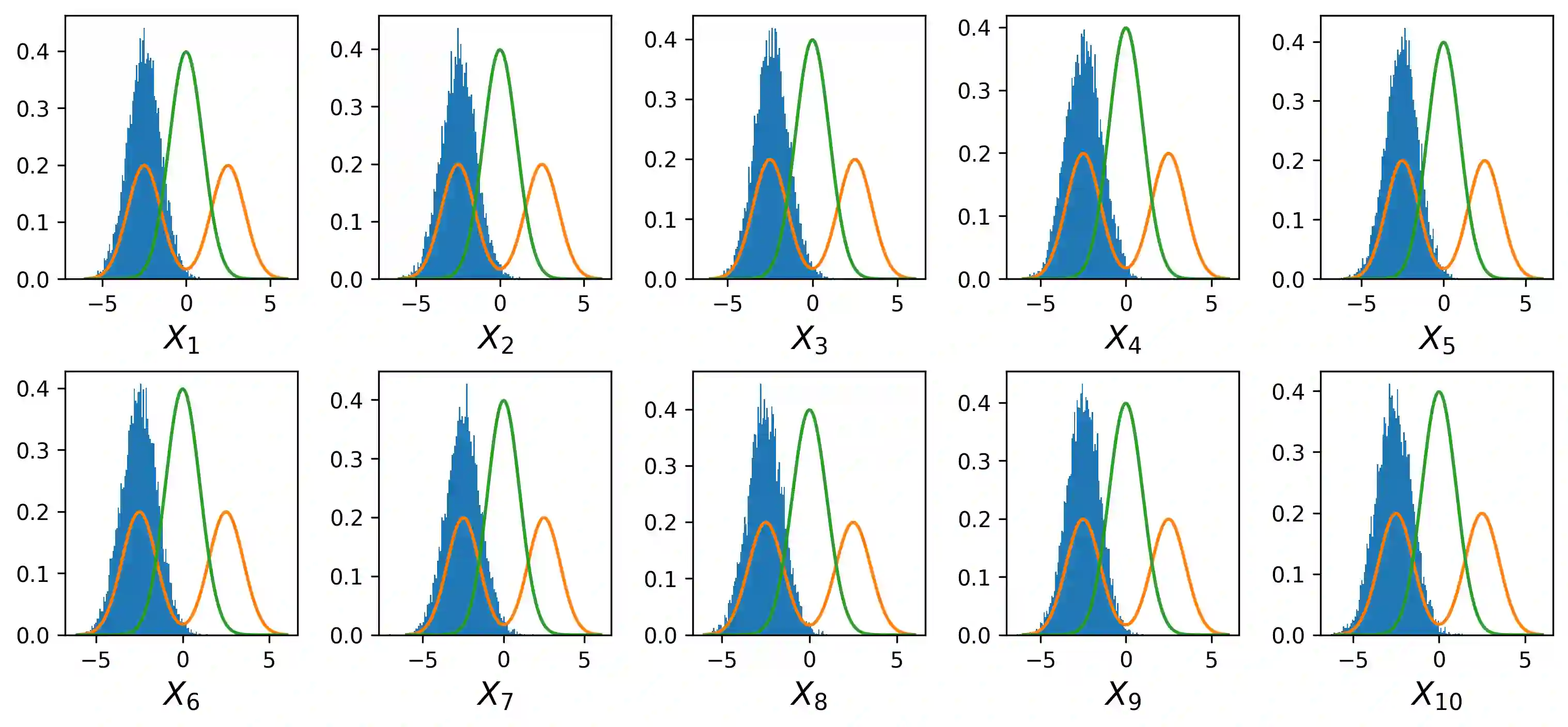
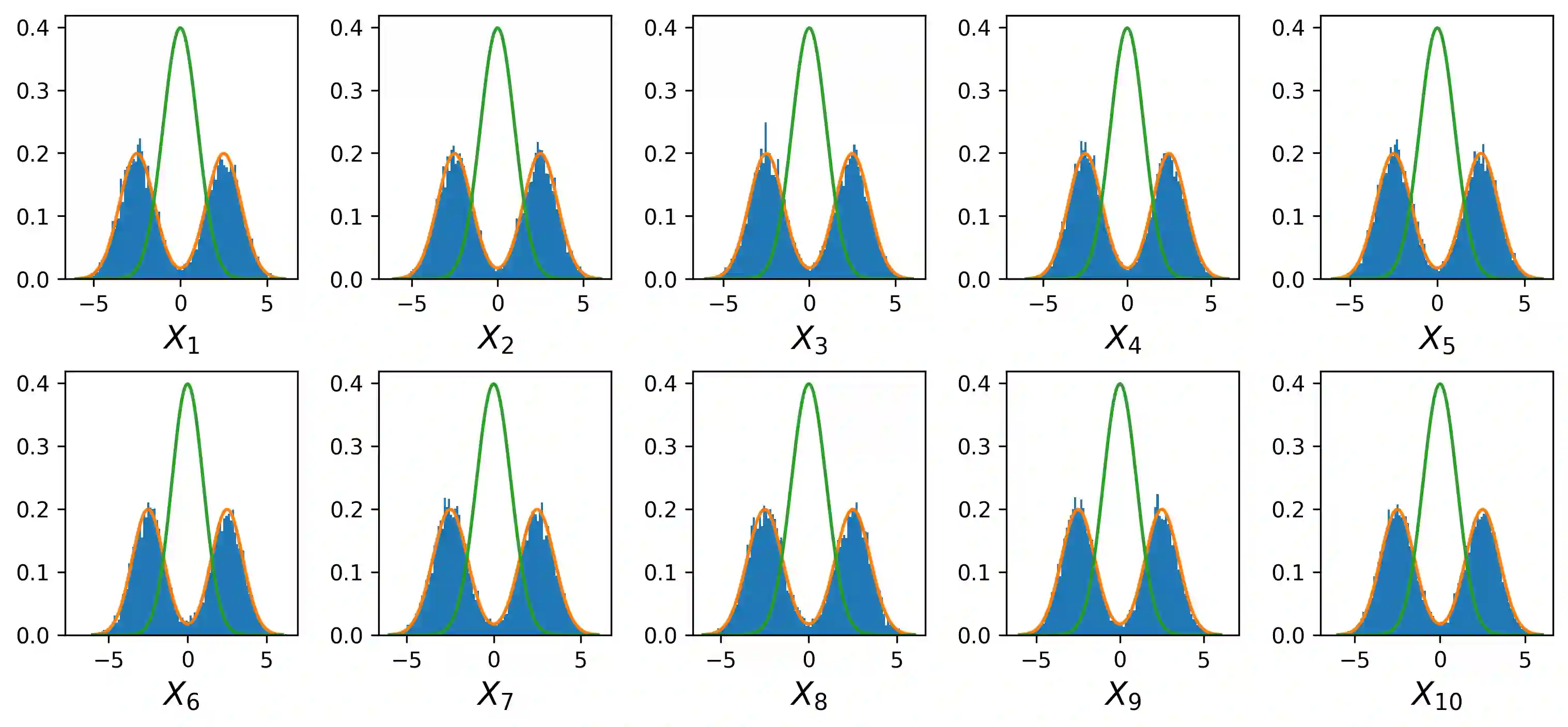
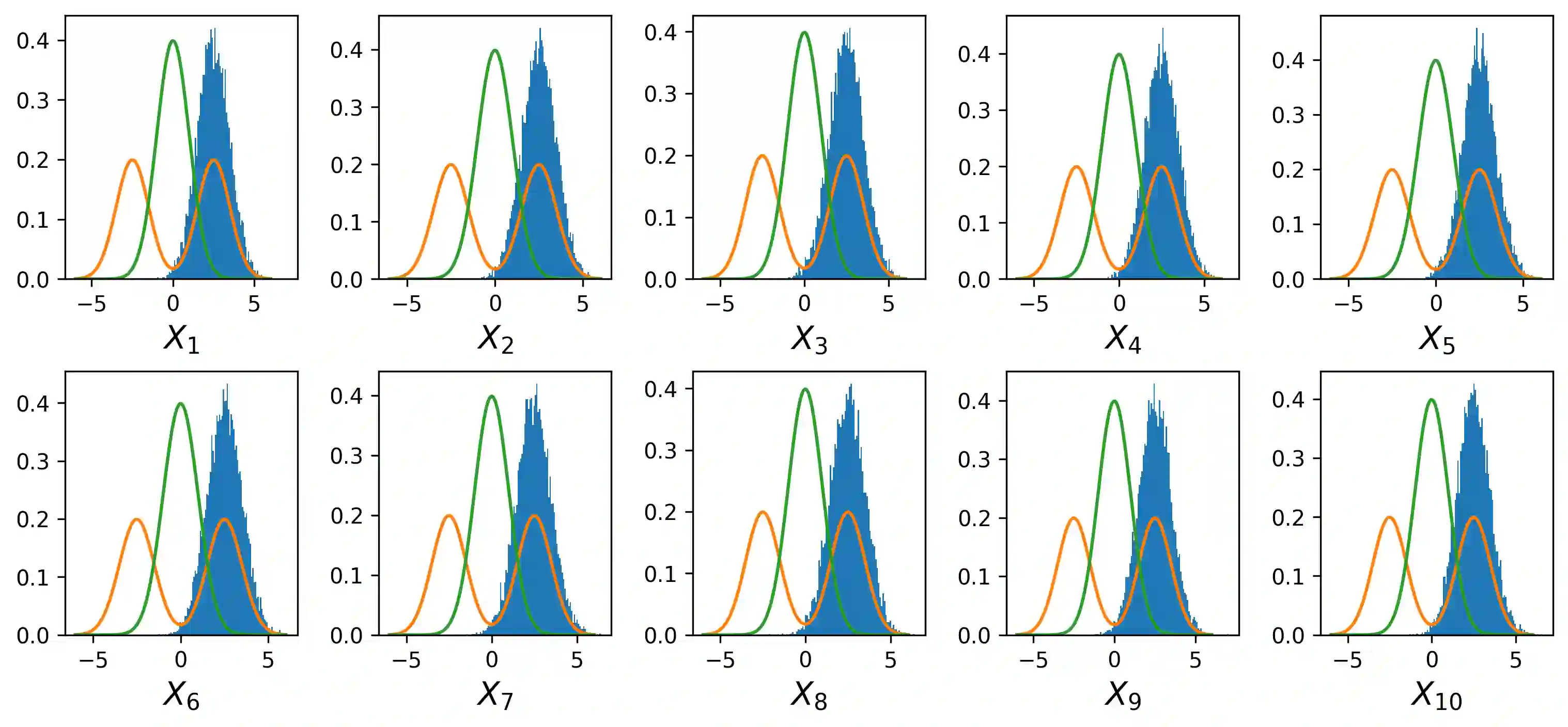
Probability density function estimation with weighted samples is the main foundation of all adaptive importance sampling algorithms. Classically, a target distribution is approximated either by a non-parametric model or within a parametric family. However, these models suffer from the curse of dimensionality or from their lack of flexibility. In this contribution, we suggest to use as the approximating model a distribution parameterised by a variational autoencoder. We extend the existing framework to the case of weighted samples by introducing a new objective function. The flexibility of the obtained family of distributions makes it as expressive as a non-parametric model, and despite the very high number of parameters to estimate, this family is much more efficient in high dimension than the classical Gaussian or Gaussian mixture families. Moreover, in order to add flexibility to the model and to be able to learn multimodal distributions, we consider a learnable prior distribution for the variational autoencoder latent variables. We also introduce a new pre-training procedure for the variational autoencoder to find good starting weights of the neural networks to prevent as much as possible the posterior collapse phenomenon to happen. At last, we explicit how the resulting distribution can be combined with importance sampling, and we exploit the proposed procedure in existing adaptive importance sampling algorithms to draw points from a target distribution and to estimate a rare event probability in high dimension on two multimodal problems.
翻译:暂无翻译