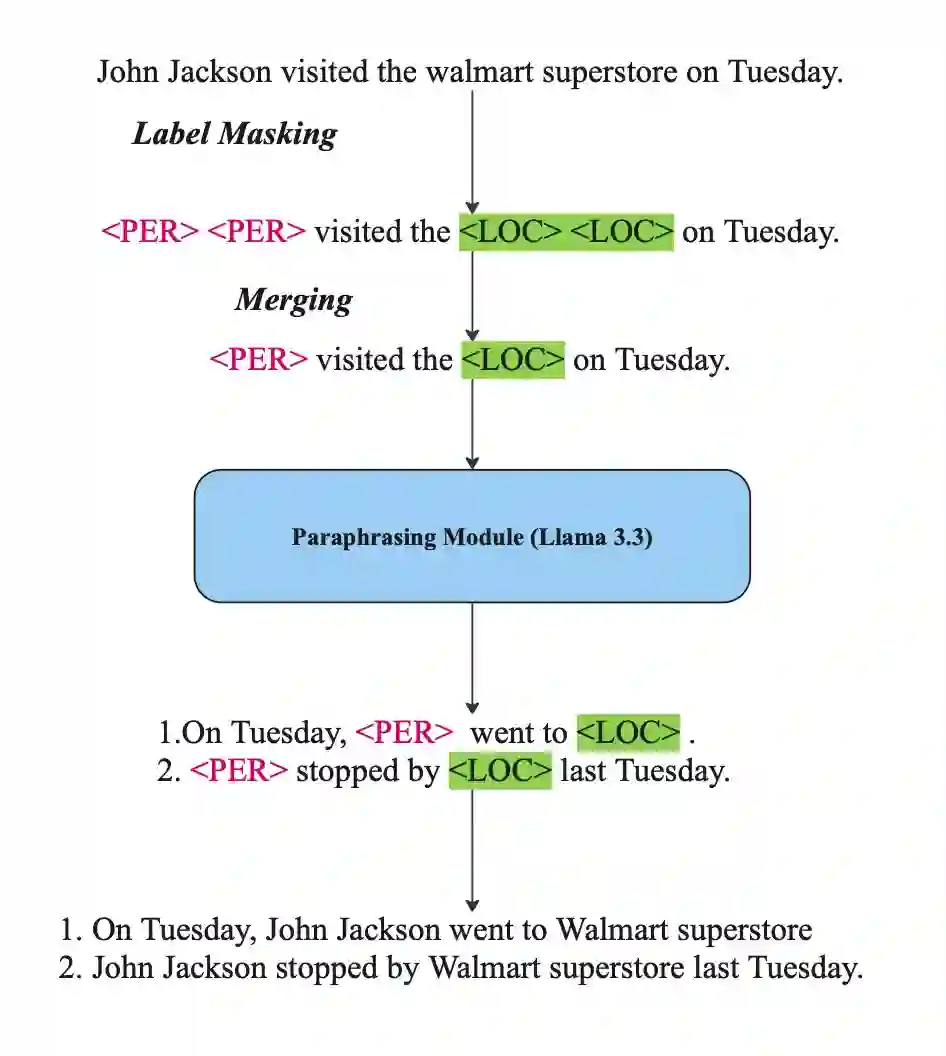
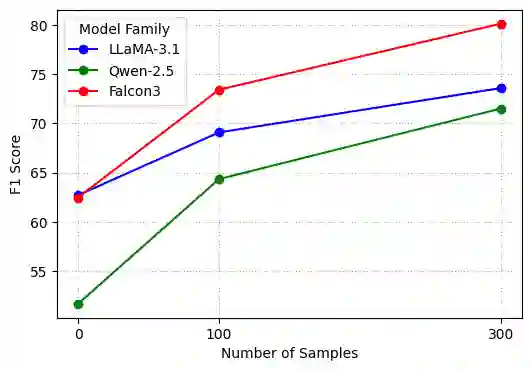
Named Entity Recognition (NER) is a critical task that requires substantial annotated data, making it challenging in low-resource scenarios where label acquisition is expensive. While zero-shot and instruction-tuned approaches have made progress, they often fail to generalize to domain-specific entities and do not effectively utilize limited available data. We present a lightweight few-shot NER framework that addresses these challenges through two key innovations: (1) a new instruction tuning template with a simplified output format that combines principles from prior IT approaches to leverage the large context window of recent state-of-the-art LLMs; (2) introducing a strategic data augmentation technique that preserves entity information while paraphrasing the surrounding context, thereby expanding our training data without compromising semantic relationships. Experiments on benchmark datasets show that our method achieves performance comparable to state-of-the-art models on few-shot and zero-shot tasks, with our few-shot approach attaining an average F1 score of 80.1 on the CrossNER datasets. Models trained with our paraphrasing approach show consistent improvements in F1 scores of up to 17 points over baseline versions, offering a promising solution for groups with limited NER training data and compute power.
翻译:命名实体识别(NER)是一项关键任务,通常需要大量标注数据,这使得其在标注获取成本高昂的低资源场景下面临挑战。尽管零样本和指令微调方法已取得进展,但它们往往难以泛化到领域特定实体,且未能有效利用有限的可用数据。本文提出一种轻量级少样本NER框架,通过两项关键创新应对这些挑战:(1)设计了一种新的指令微调模板,其简化的输出格式融合了先前指令微调方法的原理,以充分利用当前最先进大语言模型的大上下文窗口;(2)引入一种策略性数据增强技术,在保持实体信息的同时对上下文进行释义,从而在不破坏语义关系的前提下扩展训练数据。在基准数据集上的实验表明,本方法在少样本和零样本任务上取得了与最先进模型相当的性能,其中少样本方法在CrossNER数据集上的平均F1分数达到80.1。采用本释义方法训练的模型相比基线版本在F1分数上实现了最高达17个百分点的持续提升,为拥有有限NER训练数据和计算资源的群体提供了有前景的解决方案。