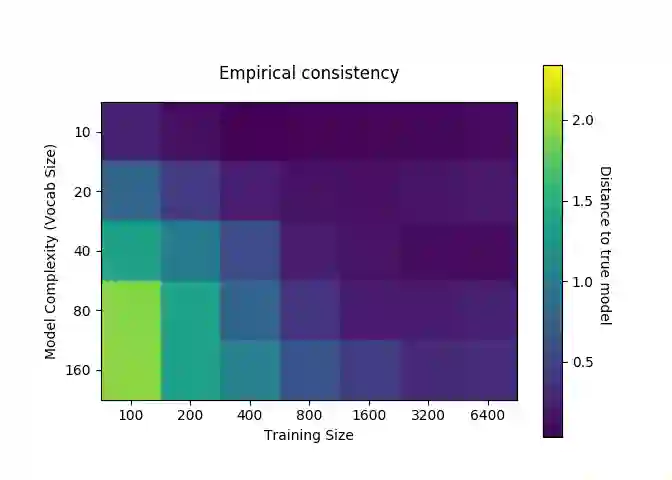
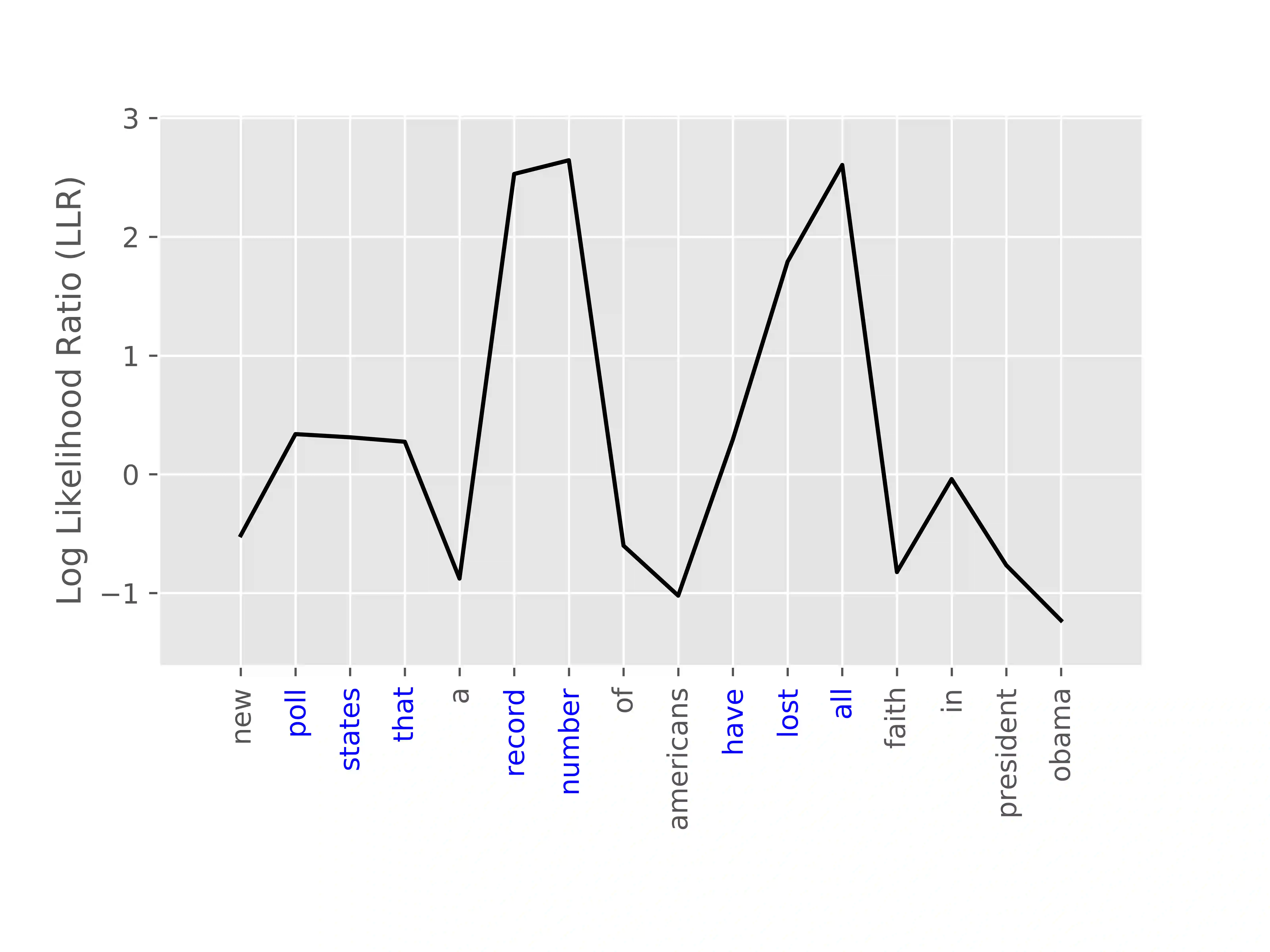
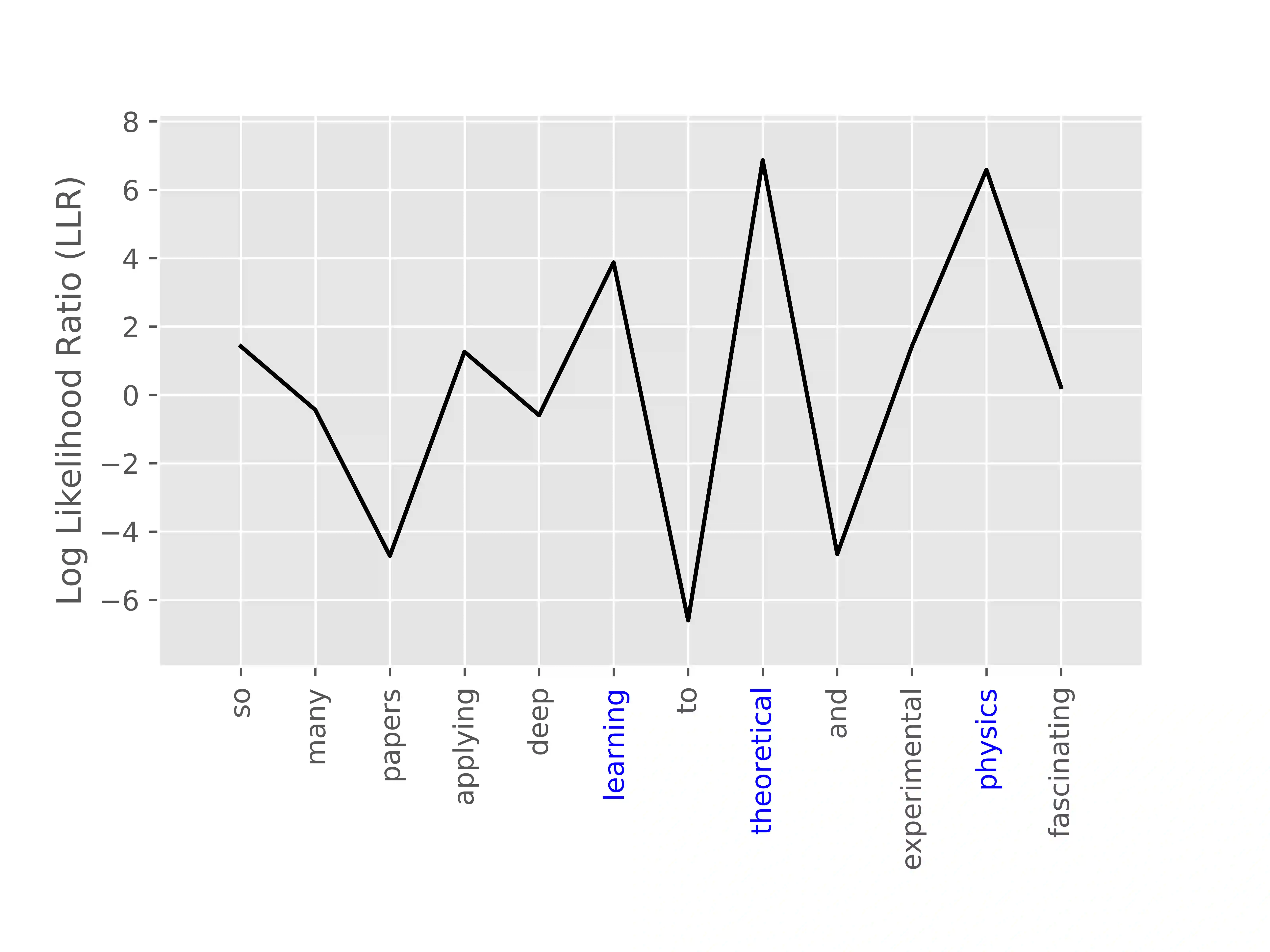
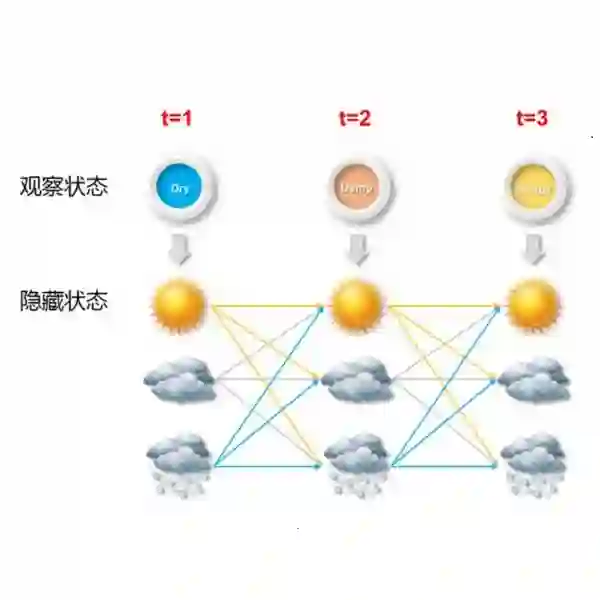
We present PROPS, a lightweight transfer learning mechanism for sequential data. PROPS learns probabilistic perturbations around the predictions of one or more arbitrarily complex, pre-trained black box models (such as recurrent neural networks). The technique pins the black-box prediction functions to "source nodes" of a hidden Markov model (HMM), and uses the remaining nodes as "perturbation nodes" for learning customized perturbations around those predictions. In this paper, we describe the PROPS model, provide an algorithm for online learning of its parameters, and demonstrate the consistency of this estimation. We also explore the utility of PROPS in the context of personalized language modeling. In particular, we construct a baseline language model by training a LSTM on the entire Wikipedia corpus of 2.5 million articles (around 6.6 billion words), and then use PROPS to provide lightweight customization into a personalized language model of President Donald J. Trump's tweeting. We achieved good customization after only 2,000 additional words, and find that the PROPS model, being fully probabilistic, provides insight into when President Trump's speech departs from generic patterns in the Wikipedia corpus. Python code (for both the PROPS training algorithm as well as experiment reproducibility) is available at https://github.com/cylance/perturbed-sequence-model.
翻译:我们提出PROPPS,这是一个用于连续数据的轻量级传输学习机制;PROPS在预测一个或多个任意复杂、事先训练的黑盒模型(例如经常性神经网络)时,会了解概率性扰动。技术将黑盒预测功能钉在隐藏的Markov模型(HMM)的“源节点”上,然后用其余节点作为“扰动节点”,学习这些预测的定制扰动。在本文中,我们描述PROPS模型,为在线学习其参数提供算法,并展示这一估计的一致性。我们还探讨PROPS在个人化语言模型中是否有用。特别是,我们通过在整个维基百科堆中培训一个LSTM(约6.6亿字),将黑盒预测功能锁定为“源节点”,然后使用PROPS为Donald J. Trump's的个性化语言模型提供轻量量的定制。我们只用了2,000字后就实现了良好的定制,发现PROPS模型是完全可靠的,在个人化语言模型中提供了深入的视野,当Trampbus/rampbisal 正在将PRApreabes 用于PRAmbreal 的版本的版本,作为Bisals 和Mismalmalmalbismalbisalbismex