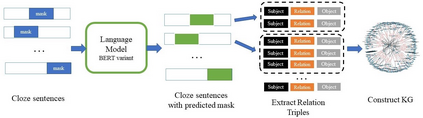
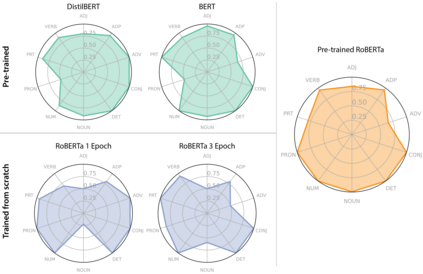
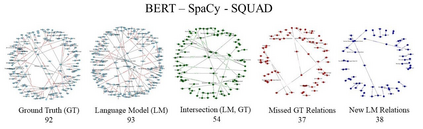
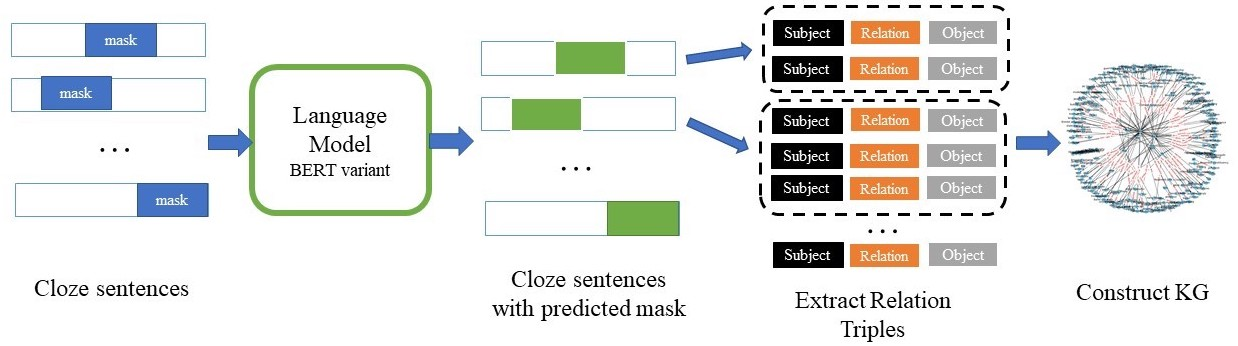
Transformer-based language models trained on large text corpora have enjoyed immense popularity in the natural language processing community and are commonly used as a starting point for downstream tasks. While these models are undeniably useful, it is a challenge to quantify their performance beyond traditional accuracy metrics. In this paper, we compare BERT-based language models through snapshots of acquired knowledge at sequential stages of the training process. Structured relationships from training corpora may be uncovered through querying a masked language model with probing tasks. We present a methodology to unveil a knowledge acquisition timeline by generating knowledge graph extracts from cloze "fill-in-the-blank" statements at various stages of RoBERTa's early training. We extend this analysis to a comparison of pretrained variations of BERT models (DistilBERT, BERT-base, RoBERTa). This work proposes a quantitative framework to compare language models through knowledge graph extraction (GED, Graph2Vec) and showcases a part-of-speech analysis (POSOR) to identify the linguistic strengths of each model variant. Using these metrics, machine learning practitioners can compare models, diagnose their models' behavioral strengths and weaknesses, and identify new targeted datasets to improve model performance.
翻译:以大型文本公司为培训对象的基于变换语言模型在自然语言处理社区受到极大欢迎,并被普遍用作下游任务的起点。这些模型虽然不可否认有用,但很难在传统精确度尺度之外对其业绩进行量化。在本文中,我们通过在培训过程的连续阶段对基于BERT的基于BERT的语言模型进行对比,通过在培训过程中的相继阶段对获得的知识进行切片比较。培训公司的结构关系可以通过查询带有测试任务的蒙面语言模型来发现。我们提出一种方法,通过在RoBERTA早期培训的各个阶段从“填充空白”的“Cluze-ploin-the-blank”语句中生成知识图表摘录来公布知识获取时间表。我们扩大这一分析的范围,以比较BERT模型(DTILBERT,BERT-Basebase, RoBERTTTAT)的预先培训变异。这项工作提出了一个定量框架,通过知识图提取(GED, Grap2Vec)来比较语言模型(POSOR),并展示部分语言分析,以确定每个模型变式的语言优势。使用这些计量模型、机器学习从业人员可以比较其有目标的弱点和行为模型。