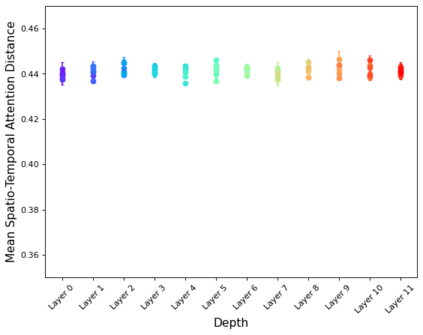
We present Multiscale Vision Transformers (MViT) for video and image recognition, by connecting the seminal idea of multiscale feature hierarchies with transformer models. Multiscale Transformers have several channel-resolution scale stages. Starting from the input resolution and a small channel dimension, the stages hierarchically expand the channel capacity while reducing the spatial resolution. This creates a multiscale pyramid of features with early layers operating at high spatial resolution to model simple low-level visual information, and deeper layers at spatially coarse, but complex, high-dimensional features. We evaluate this fundamental architectural prior for modeling the dense nature of visual signals for a variety of video recognition tasks where it outperforms concurrent vision transformers that rely on large scale external pre-training and are 5-10x more costly in computation and parameters. We further remove the temporal dimension and apply our model for image classification where it outperforms prior work on vision transformers. Code is available at: https://github.com/facebookresearch/SlowFast
翻译:我们通过将多尺度特征等级与变压器模型连接起来,为视频和图像识别提出多尺度视觉变异器(MViT)的初始概念。多尺度变异器有多个频道分辨率级。从输入分辨率和小频道层面开始,从输入分辨率和小频道层面分级扩展频道容量,同时降低空间分辨率。这创造了一个多尺度的功能金字塔,其早期层以高空间分辨率运行,以模拟简单的低水平视觉信息,以及空间粗糙但复杂、高维特征的更深层。我们评估了这一基本建筑,以模拟各种视频识别任务的视觉信号的密集性质,在这些任务中,它优于依赖大规模外部预培训的同步视觉变异器,在计算和参数方面成本为5-10x。我们进一步删除了时间层面,并在图像分类中应用了我们的模型,在图像分类中它优于先前关于视觉变异器的工作。代码见: https://github.com/facebourresearch/SlowFast/SlowFast。