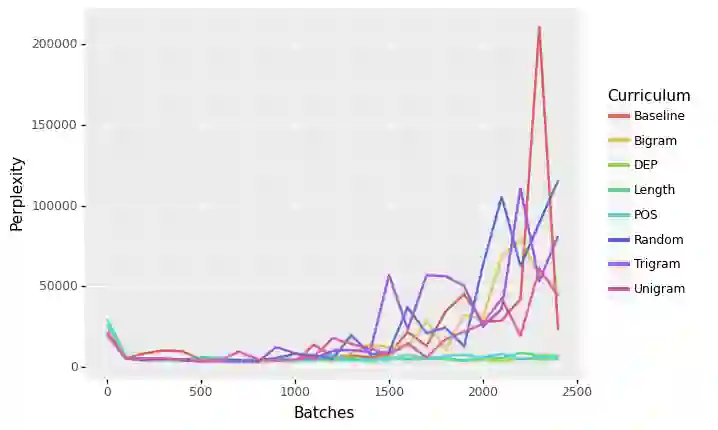
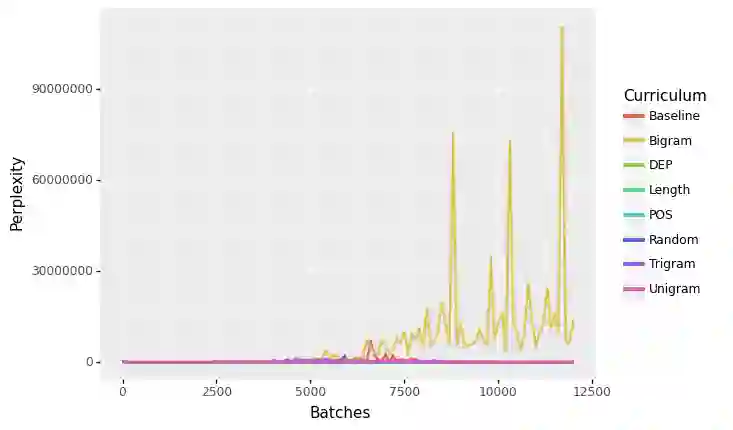
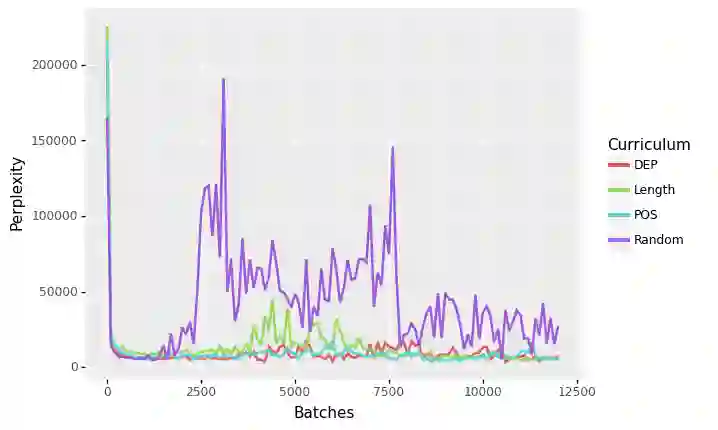
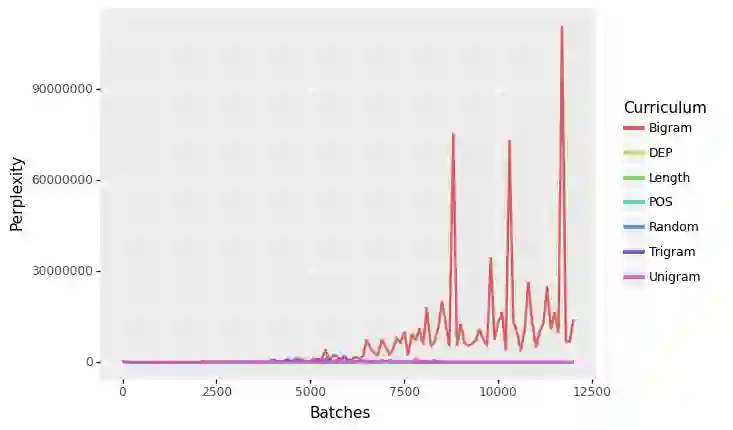
Language Models like ELMo and BERT have provided robust representations of natural language, which serve as the language understanding component for a diverse range of downstream tasks.Curriculum learning is a method that employs a structured training regime instead, which has been leveraged in computer vision and machine translation to improve model training speed and model performance. While language models have proven transformational for the natural language processing community, these models have proven expensive, energy-intensive, and challenging to train. In this work, we explore the effect of curriculum learning on language model pretraining using various linguistically motivated curricula and evaluate transfer performance on the GLUE Benchmark. Despite a broad variety of training methodologies and experiments we do not find compelling evidence that curriculum learning methods improve language model training.
翻译:语言模型,如ELMO和BERT等语言模型,为各种下游任务提供了有力的自然语言表现,这些语言模型是语言理解的组成部分。 学习是采用结构化培训制度的一种方法,而采用结构化培训制度,在计算机愿景和机器翻译中加以利用,以提高模式培训速度和模型性能。虽然语言模型已证明对自然语言处理界具有转型作用,但这些模型证明是昂贵、耗能和具有挑战性的培训。在这项工作中,我们探讨课程学习对语言模型预培训的影响,利用各种语言激励课程,并评估GLUE基准的转让绩效。尽管我们发现许多培训方法和实验都无法令人信服地证明课程学习方法改善了语言模型培训。