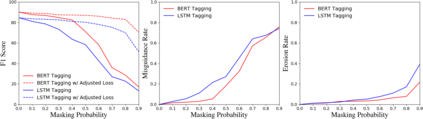
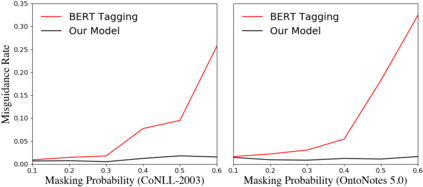
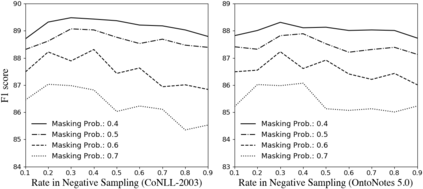
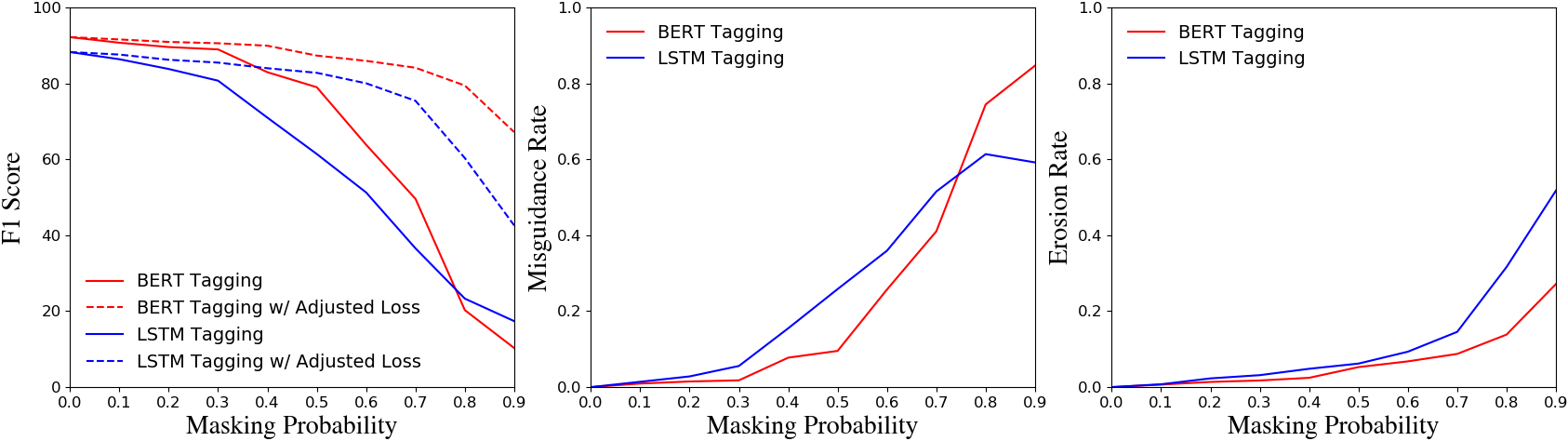
In many scenarios, named entity recognition (NER) models severely suffer from unlabeled entity problem, where the entities of a sentence may not be fully annotated. Through empirical studies performed on synthetic datasets, we find two causes of the performance degradation. One is the reduction of annotated entities and the other is treating unlabeled entities as negative instances. The first cause has less impact than the second one and can be mitigated by adopting pretraining language models. The second cause seriously misguides a model in training and greatly affects its performances. Based on the above observations, we propose a general approach that is capable of eliminating the misguidance brought by unlabeled entities. The core idea is using negative sampling to keep the probability of training with unlabeled entities at a very low level. Experiments on synthetic datasets and real-world datasets show that our model is robust to unlabeled entity problem and surpasses prior baselines. On well-annotated datasets, our model is competitive with state-of-the-art method.
翻译:在许多情况中,命名实体识别模型严重受到未标实体问题的影响,在这种情况下,一个句子的实体可能没有得到充分说明。通过对合成数据集进行的经验性研究,我们发现性能退化的原因有两种:一种是减少附加说明的实体,另一种是将未标实体视为负面实例;第一个原因的影响小于第二个原因,可以通过采用预培训语言模型来减轻。第二个原因严重误导培训模型,并严重影响其绩效。根据上述观察,我们提出了一个能够消除未标实体带来的错误指导的一般方法。核心想法是利用负面抽样将与未标实体培训的可能性保持在非常低的水平。关于合成数据集和现实世界数据集的实验表明,我们的模型对于未标实体问题是强大的,并且超过了以前的基线。关于附加说明良好的数据集,我们的模型与最先进的方法具有竞争力。