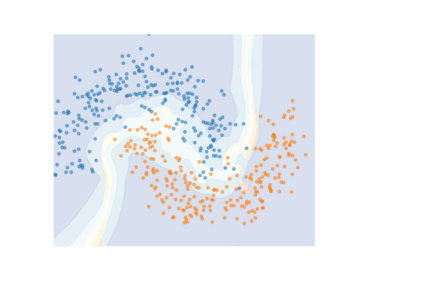
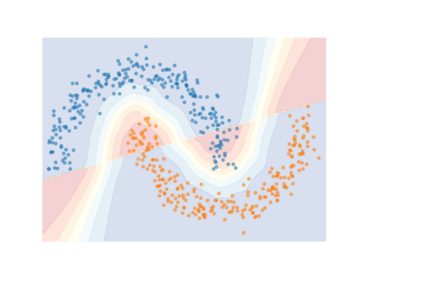
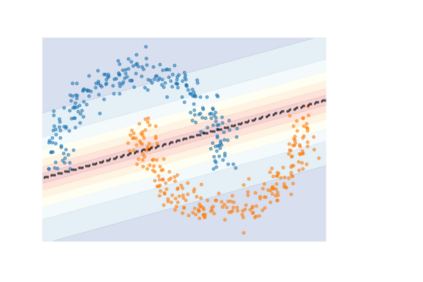
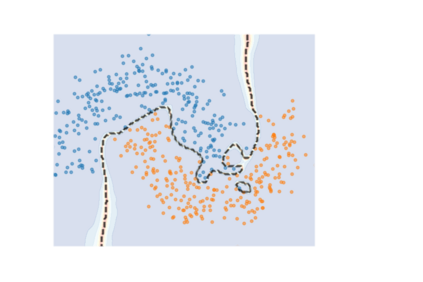
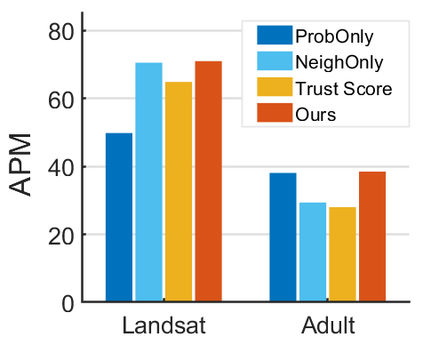
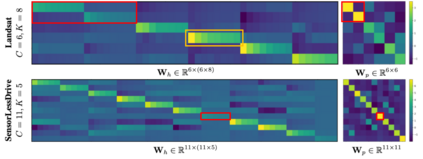
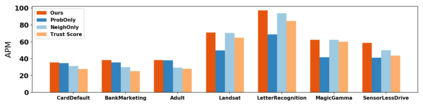
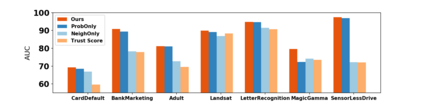
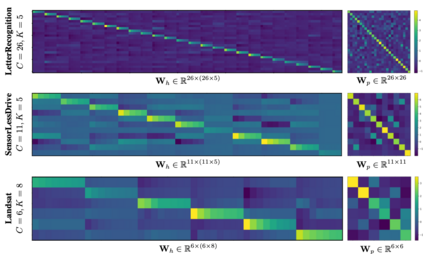
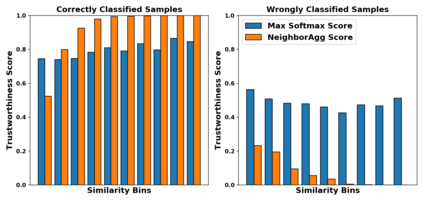
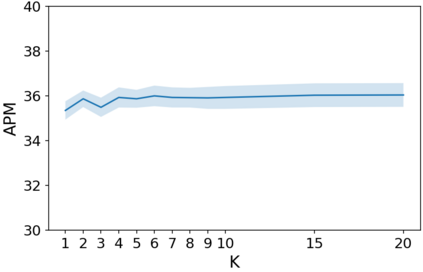
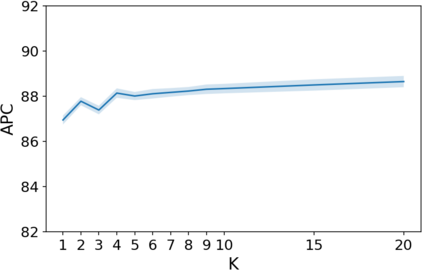
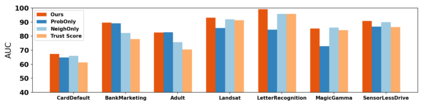
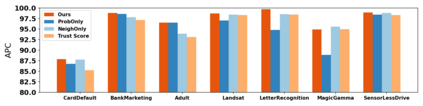
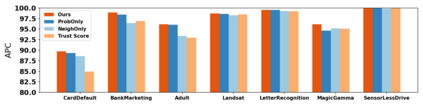
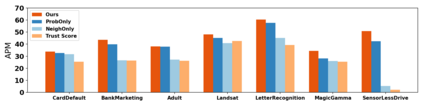
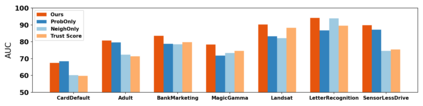
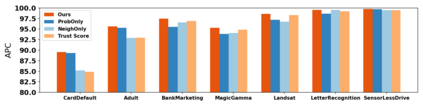
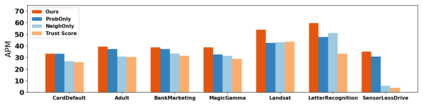
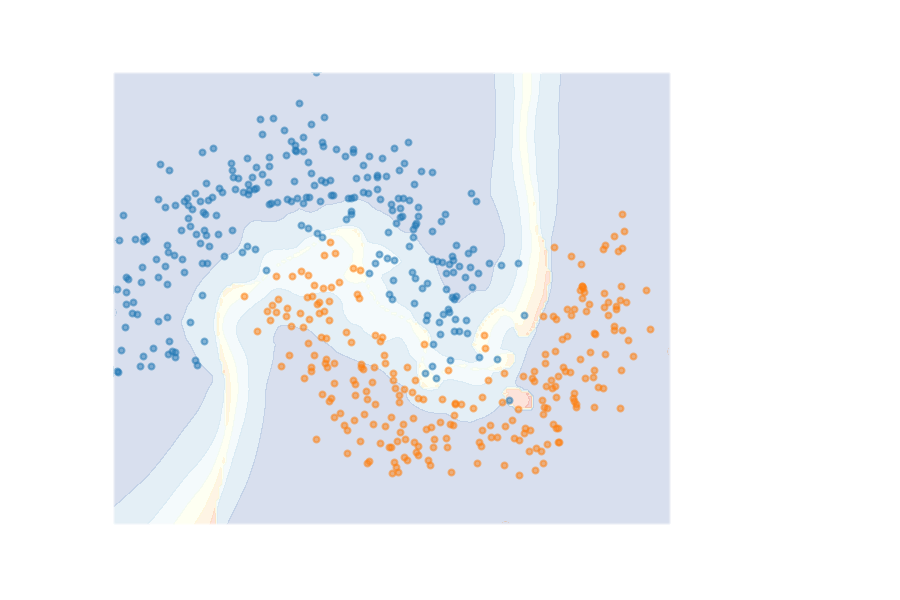
How do we know when the predictions made by a classifier can be trusted? This is a fundamental problem that also has immense practical applicability, especially in safety-critical areas such as medicine and autonomous driving. The de facto approach of using the classifier's softmax outputs as a proxy for trustworthiness suffers from the over-confidence issue; while the most recent works incur problems such as additional retraining cost and accuracy versus trustworthiness trade-off. In this work, we argue that the trustworthiness of a classifier's prediction for a sample is highly associated with two factors: the sample's neighborhood information and the classifier's output. To combine the best of both worlds, we design a model-agnostic post-hoc approach NeighborAgg to leverage the two essential information via an adaptive neighborhood aggregation. Theoretically, we show that NeighborAgg is a generalized version of a one-hop graph convolutional network, inheriting the powerful modeling ability to capture the varying similarity between samples within each class. We also extend our approach to the closely related task of mislabel detection and provide a theoretical coverage guarantee to bound the false negative. Empirically, extensive experiments on image and tabular benchmarks verify our theory and suggest that NeighborAgg outperforms other methods, achieving state-of-the-art trustworthiness performance.
翻译:我们如何知道何时可以相信一个分类者的预测? 这是一个根本性的问题, 特别是在医学和自主驾驶等安全关键领域, 也具有巨大的实际适用性。 使用分类者的软成份作为可信任的替代物的实际方法, 与过度信任问题有关; 虽然最近的工作产生了额外的再培训成本和准确性相对于可信赖性交易等问题。 在这项工作中, 我们争论说, 分类者对抽样的预测的可信度与两个因素密切相关: 抽样的邻里信息和分类者的输出。 为了将两个世界的最佳组合起来, 我们设计了一种模型级的后热处理方法, 以便通过适应性邻里汇总来利用这两种基本信息。 从理论上讲, 我们表明, NeighborAgg 是一手图革命网络的通用版本, 继承了强大的模型能力, 以捕捉每类内不同相似的样本。 我们还将我们的方法推广到与错误标签检测密切相关的任务, 并提供理论范围, 以近似值为基础, 来验证我们的模型。