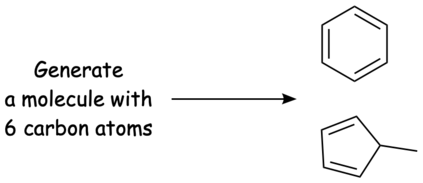
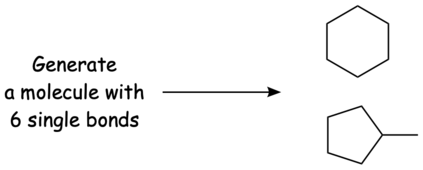
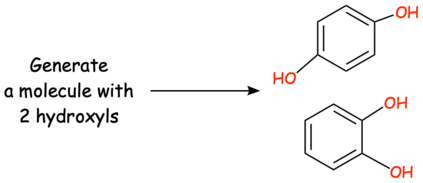
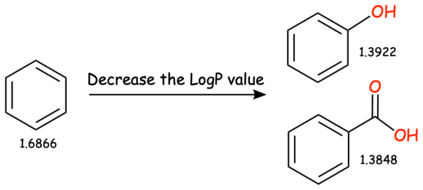
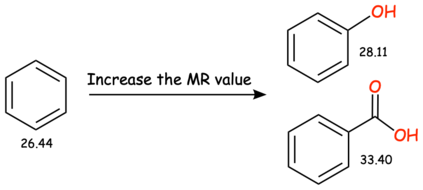
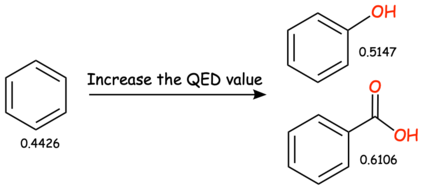
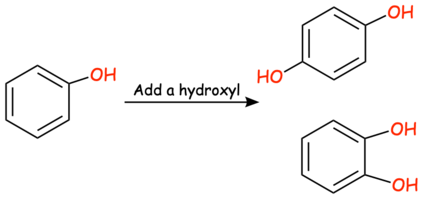
In this paper, we propose Text-based Open Molecule Generation Benchmark (TOMG-Bench), the first benchmark to evaluate the open-domain molecule generation capability of LLMs. TOMG-Bench encompasses a dataset of three major tasks: molecule editing (MolEdit), molecule optimization (MolOpt), and customized molecule generation (MolCustom). Each major task further contains three subtasks, while each subtask comprises 5,000 test samples. Given the inherent complexity of open molecule generation evaluation, we also developed an automated evaluation system that helps measure both the quality and the accuracy of the generated molecules. Our comprehensive benchmarking of 25 LLMs reveals the current limitations as well as potential areas for improvement in text-guided molecule discovery. Furthermore, we propose OpenMolIns, a specialized instruction tuning dataset established for solving challenges raised by TOMG-Bench. Fine-tuned on OpenMolIns, Llama3.1-8B could outperform all the open-source general LLMs, even surpassing GPT-3.5-turbo by 46.5\% on TOMG-Bench. Our codes and datasets are available through https://github.com/phenixace/TOMG-Bench.
翻译:暂无翻译