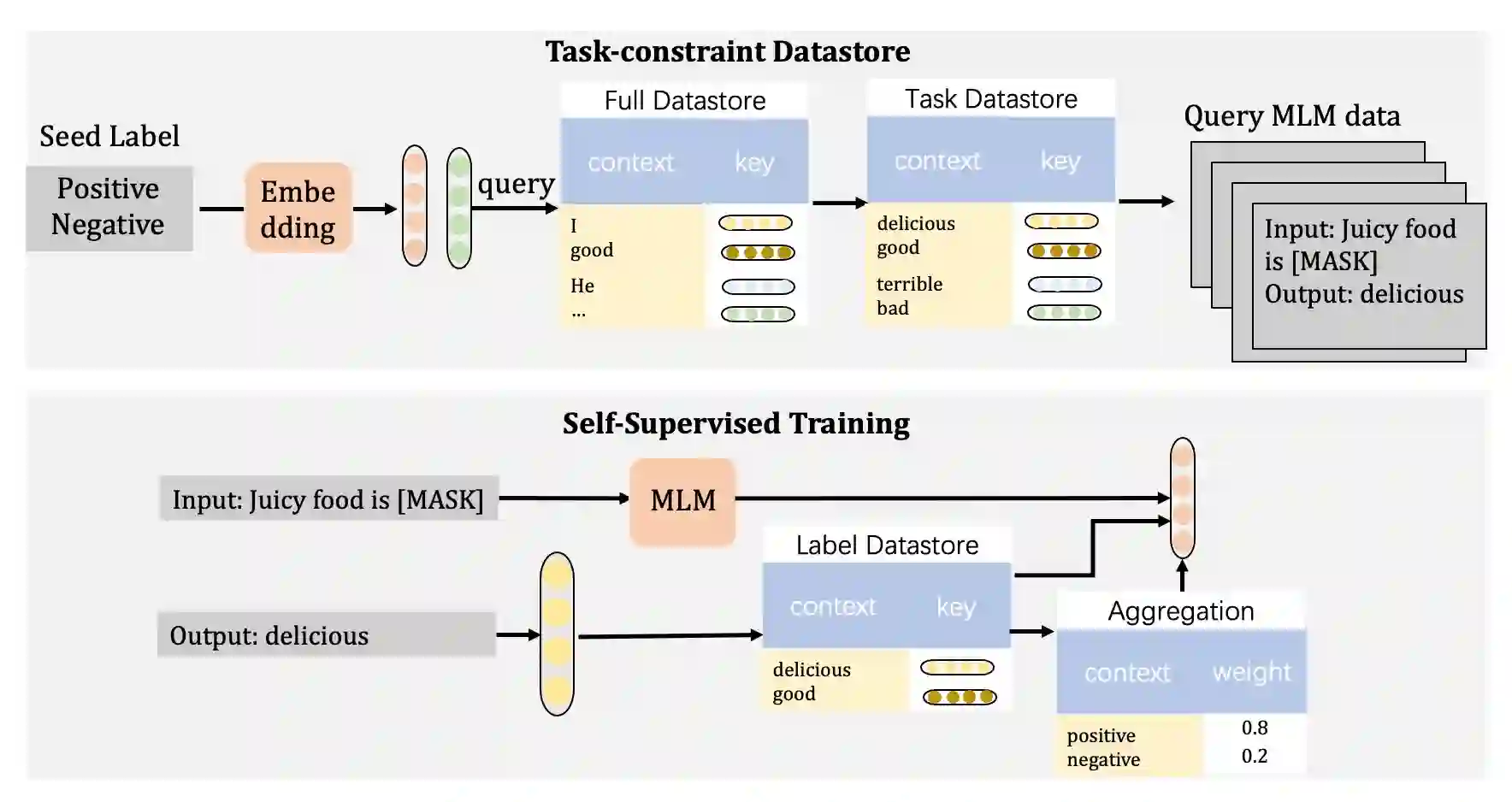
With increasing scale, large language models demonstrate both quantitative improvement and new qualitative capabilities, especially as zero-shot learners, like GPT-3. However, these results rely heavily on delicate prompt design and large computation. In this work, we explore whether the strong zero-shot ability could be achieved at a smaller model scale without any external supervised data. To achieve this goal, we revisit masked language modeling and present a geometry-guided self-supervised learning method (Go-tuningfor short) by taking a small number of task-aware self-supervised data to update language models further. Experiments show that Go-tuning can enable T5-small (80M) competitive zero-shot results compared with large language models, such as T5-XL (3B). We also apply Go-tuning on multi-task settings and develop a multi-task model, mgo-T5 (250M). It can reach the average performance of OPT (175B) on 9 datasets.
翻译:随着规模的扩大,大型语言模型显示出数量上的改进和新的质量能力,特别是像GPT-3这样的零点学习者。然而,这些结果严重依赖微妙的迅速设计和大规模计算。在这项工作中,我们探讨强力零点能力能否在没有外部监督数据的情况下在较小的模型规模上实现。为实现这一目标,我们重新研究隐形语言模型,并推出一种以几何制导的自我监督学习方法(短调),方法是利用少量任务自视数据来进一步更新语言模型。实验显示,Go调能够使T5-小型(80M)有竞争力的零点结果与大型语言模型(如T5-XL(3B))相比得以实现。我们还在多任务设置上应用Go-T5(250M)模型,并开发一个多任务模型(mg-T5(250M))。它可以在9个数据集上达到巴勒斯坦被占领土的平均性能(175B) 。