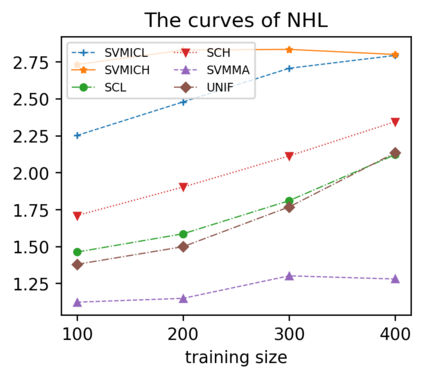
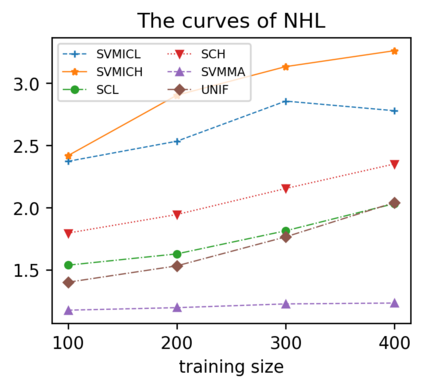
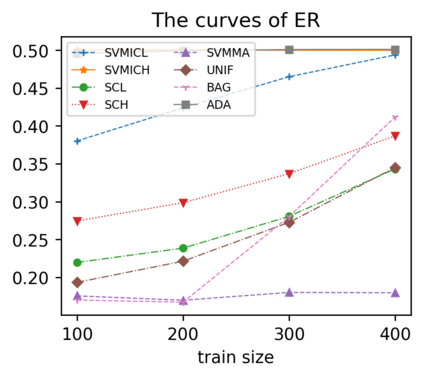
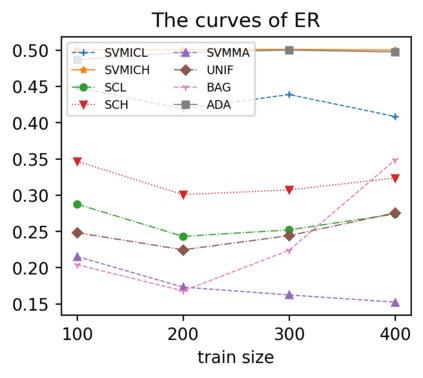
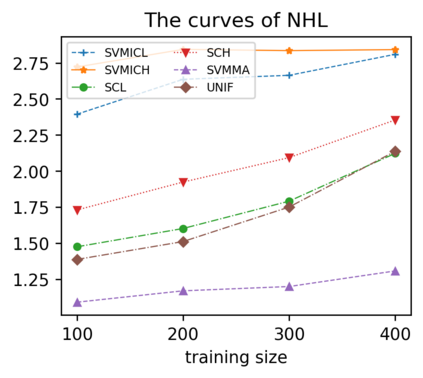
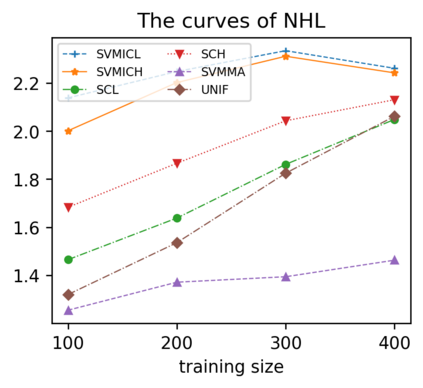
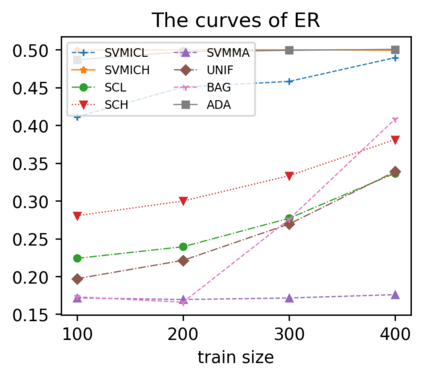
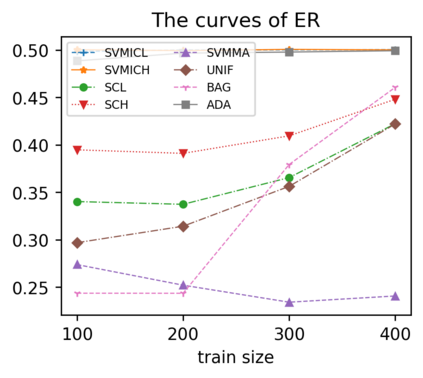
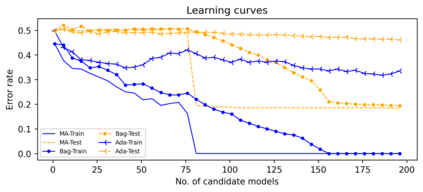
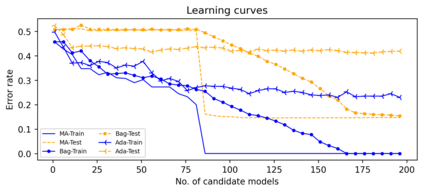
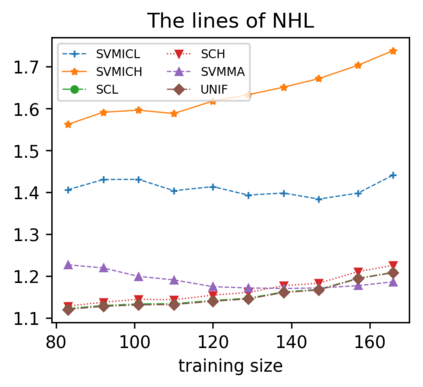
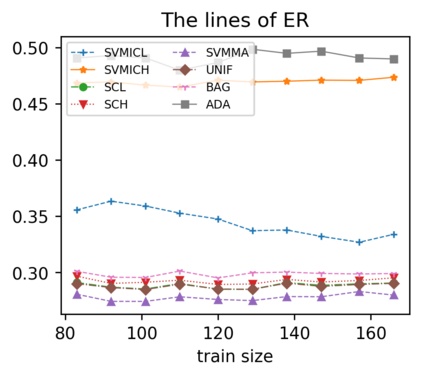
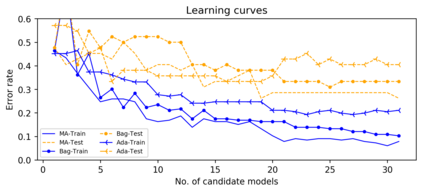
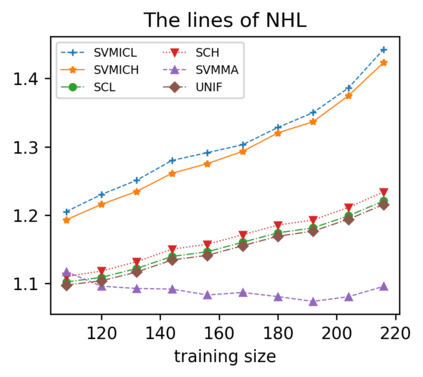
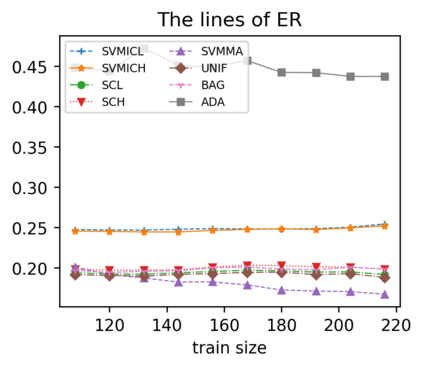
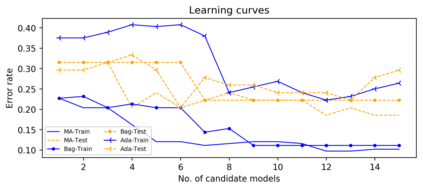
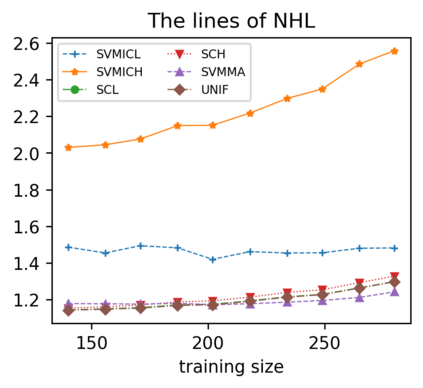
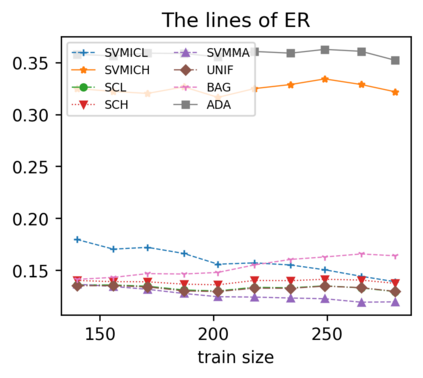
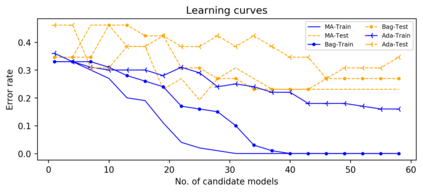
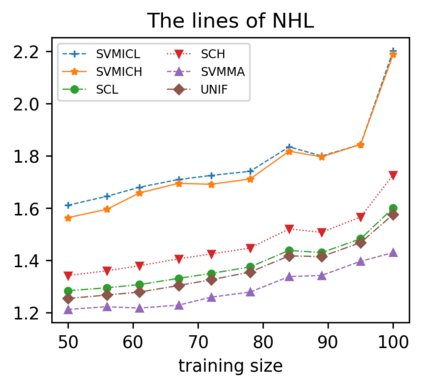
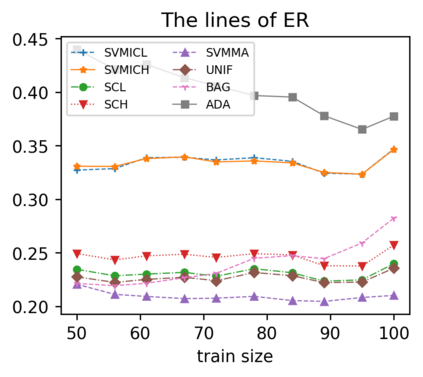
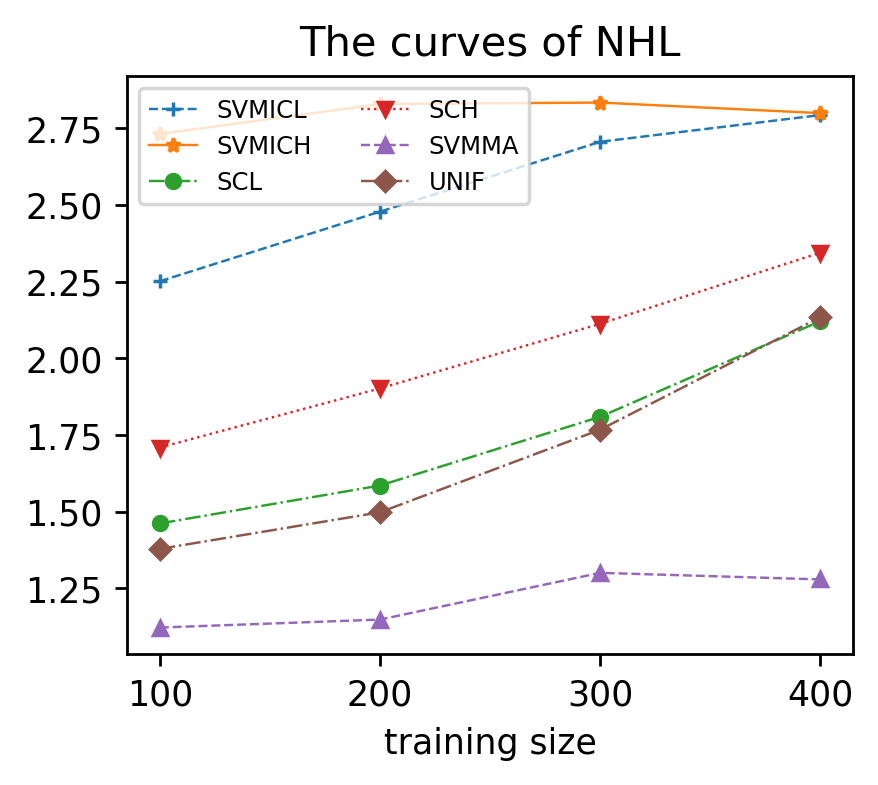
Support vector machine (SVM) is a classical tool to deal with classification problems, which is widely used in biology, statistics and machine learning and good at small sample size and high-dimensional situation. This paper proposes a model averaging method, called SVMMA, to address the uncertainty from deciding which covariates should be included for SVM and to promote its prediction ability. We offer a criterion to search the weights to combine many candidate models that are composed of different parts from the total covariates. To build up the candidate model set, we suggest to use a screening-averaging form in practice. Especially, the model averaging estimator is proved to be asymptotically optimal in the sense of achieving the lowest hinge risk among all possible combination. Finally, we do some simulation to compare the proposed model averaging method with several other model selection/averaging and ensemble learning methods, and apply to four real datasets.
翻译:支持矢量机(SVMM)是处理分类问题的经典工具,在生物学、统计和机器学习中广泛使用,并且具有小样本尺寸和高维状态,本文件提出一种称为SVMMA的模型平均法,以解决在决定哪些共变体应列入SVM的不确定性,并促进其预测能力。我们提供了一种标准,以搜索重量,将许多由全部共变体不同部分组成的候选模型结合起来。为了建立候选模型集,我们建议在实践中使用筛选-稳定格式。特别是,平均估计数据仪模型被证明是尽可能优化的,以便在所有可能的组合中实现最低临界风险。最后,我们进行了一些模拟,以便将拟议的平均方法与其他几个模型选择/稳定与共变学习方法进行比较,并适用于四个真实数据集。