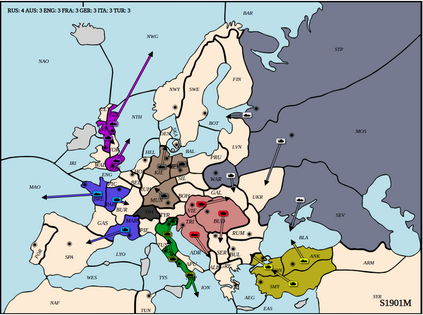
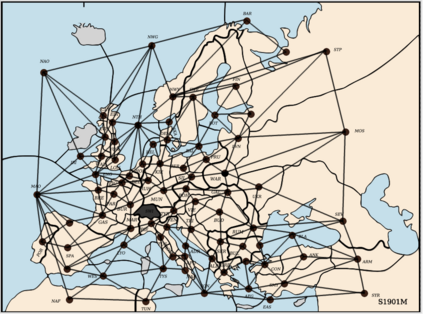
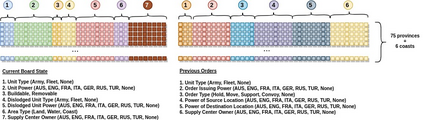
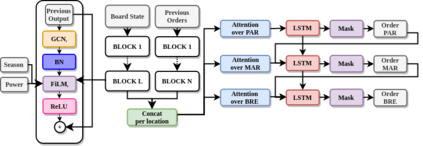
Diplomacy is a seven-player non-stochastic, non-cooperative game, where agents acquire resources through a mix of teamwork and betrayal. Reliance on trust and coordination makes Diplomacy the first non-cooperative multi-agent benchmark for complex sequential social dilemmas in a rich environment. In this work, we focus on training an agent that learns to play the No Press version of Diplomacy where there is no dedicated communication channel between players. We present DipNet, a neural-network-based policy model for No Press Diplomacy. The model was trained on a new dataset of more than 150,000 human games. Our model is trained by supervised learning (SL) from expert trajectories, which is then used to initialize a reinforcement learning (RL) agent trained through self-play. Both the SL and RL agents demonstrate state-of-the-art No Press performance by beating popular rule-based bots.
翻译:外交是一种七人、非随机、不合作的游戏,在这种游戏中,代理商通过团队合作和背叛获得资源。依赖信任和协调使外交成为在丰富环境中复杂连续的社会困境的第一个非合作性多试剂基准。在这项工作中,我们侧重于培训一名代理商,该代理商学会玩《没有新闻的外交》版,没有角色之间的专用沟通渠道。我们介绍了DipNet,一个以神经网络为基础的“没有新闻外交”政策模式。该模型是经过15万多个人类游戏新数据集的培训的。我们模型由专家轨迹的监督下学习(SL)培训,然后用于启动通过自我游戏培训的强化学习(RL)代理商。SL和RL代理商都通过击击流行的基于规则的机器人,展示了最新艺术的“不新闻”表现。