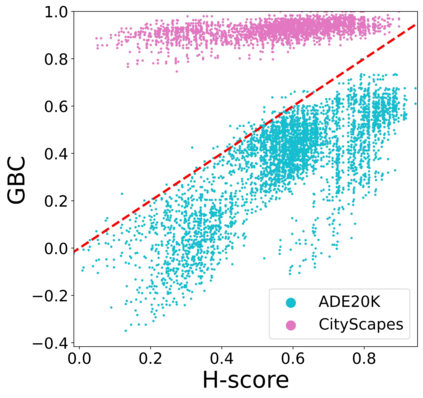
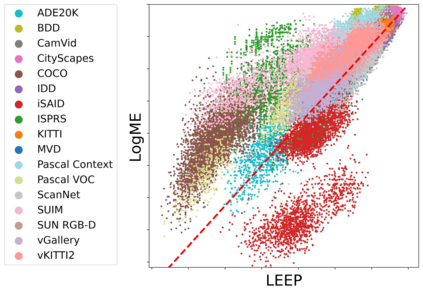
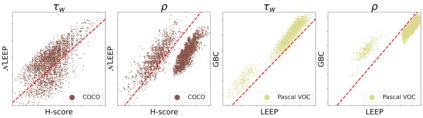
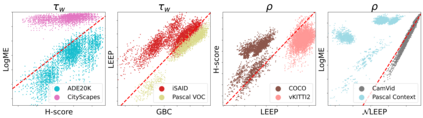
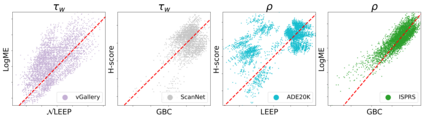
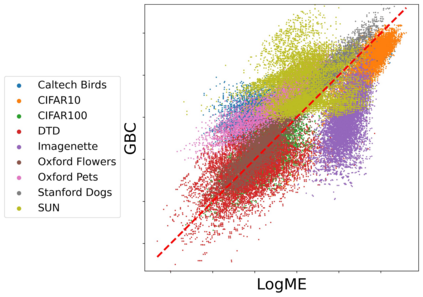
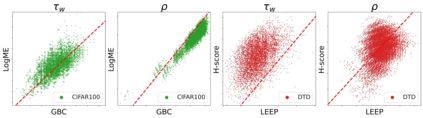
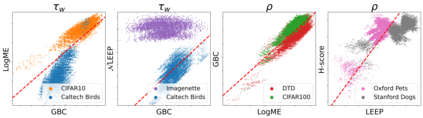
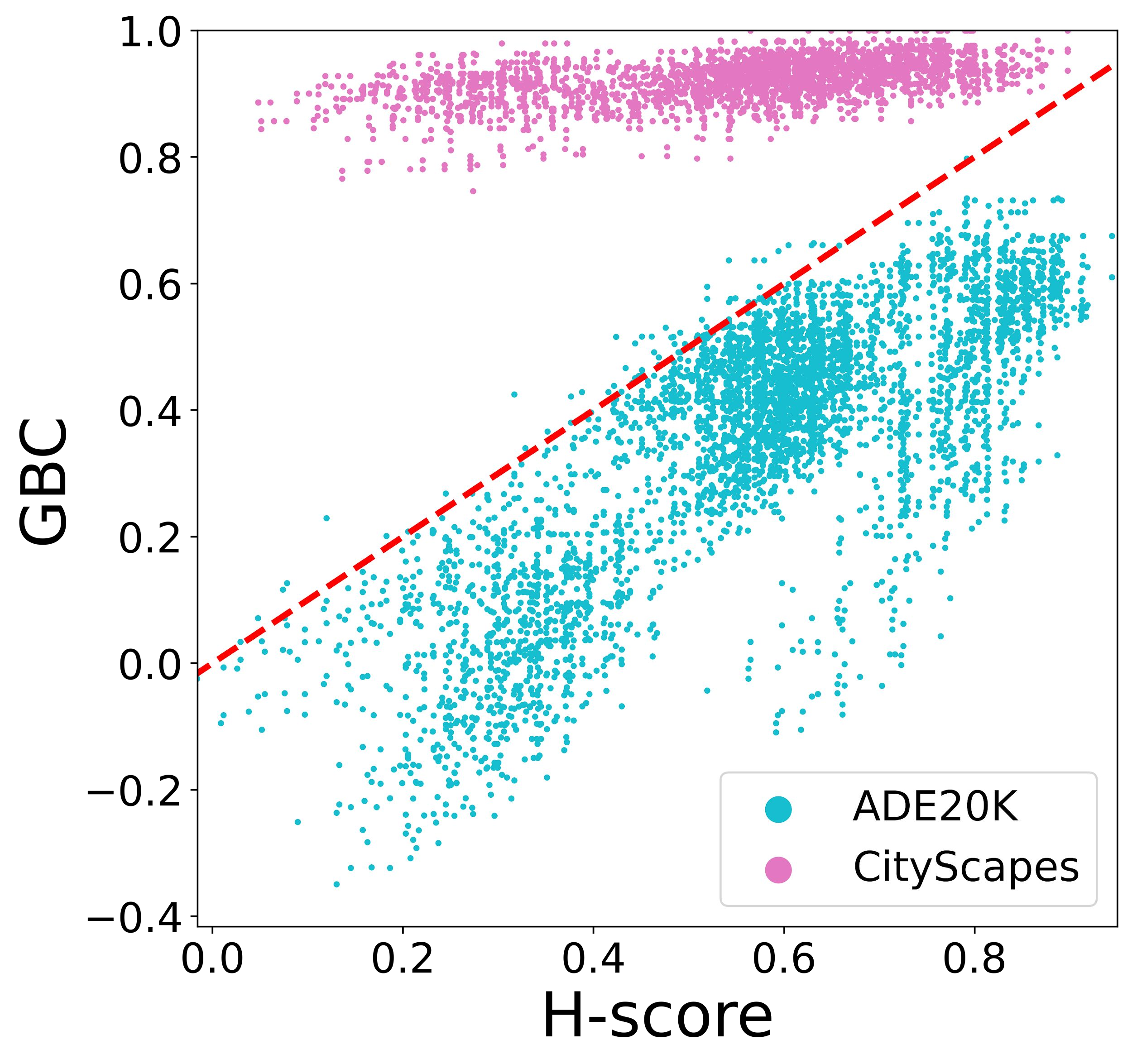
Transferability metrics is a maturing field with increasing interest, which aims at providing heuristics for selecting the most suitable source models to transfer to a given target dataset, without fine-tuning them all. However, existing works rely on custom experimental setups which differ across papers, leading to inconsistent conclusions about which transferability metrics work best. In this paper we conduct a large-scale study by systematically constructing a broad range of 715k experimental setup variations. We discover that even small variations to an experimental setup lead to different conclusions about the superiority of a transferability metric over another. Then we propose better evaluations by aggregating across many experiments, enabling to reach more stable conclusions. As a result, we reveal the superiority of LogME at selecting good source datasets to transfer from in a semantic segmentation scenario, NLEEP at selecting good source architectures in an image classification scenario, and GBC at determining which target task benefits most from a given source model. Yet, no single transferability metric works best in all scenarios.
翻译:可转让性指标是一个成熟的领域,人们越来越感兴趣,其目的是为选择最合适的来源模型向特定的目标数据集转让提供理论学,而无需对全部数据进行微调。然而,现有的工程依靠不同的纸面不同的定制实验设置,导致对哪些可转让性指标最有效作出不一致的结论。在本文中,我们进行了大规模研究,系统构建了范围很广的715k试验设置变量。我们发现,即使实验设置的微小变化也会导致对可转让性指标优于另一个指标的不同结论。然后,我们建议通过将许多试验汇总起来,更好地评估,以便能够得出更稳定的结论。结果,我们揭示了LogME在选择良好的源数据集以便从一个语义分解假设中转移的优势,NLEEP在选择图像分类假设中的良好源结构,GBC在确定哪项目标任务最受益于某个源模型时,没有一项单一的可转让性指标在所有假设中最有效。