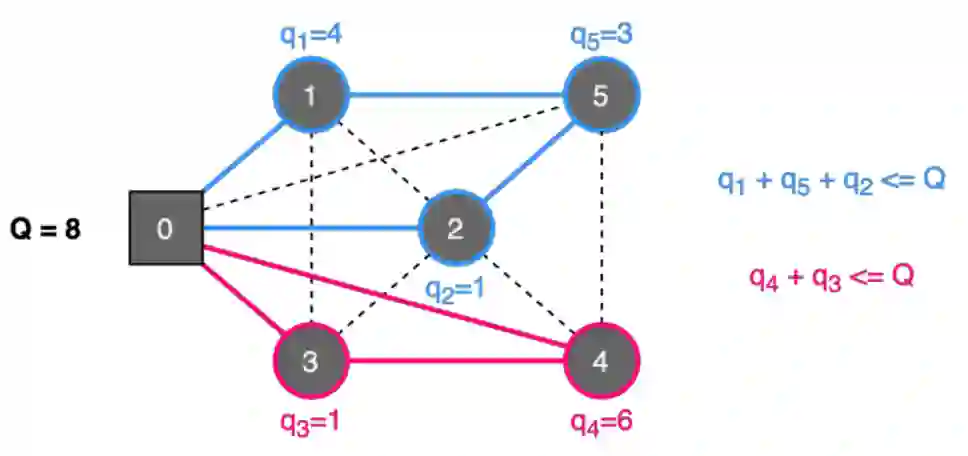
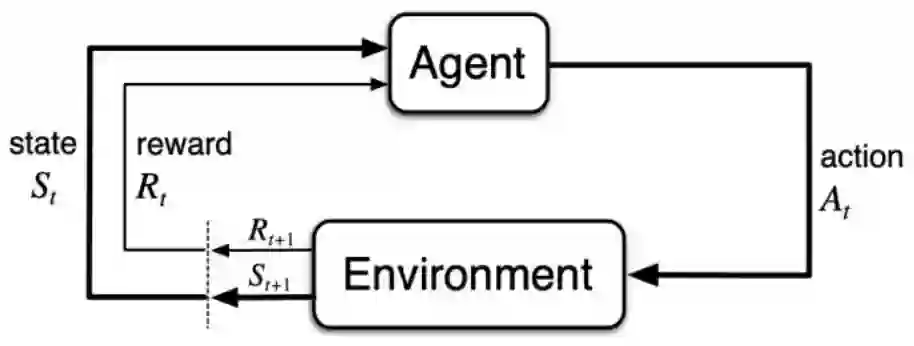
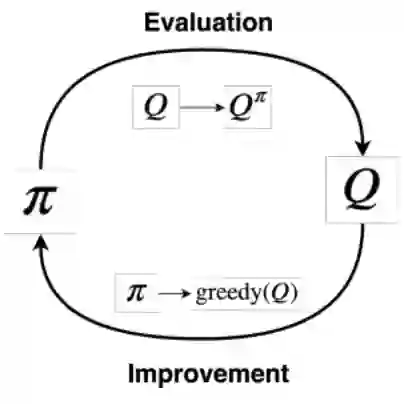
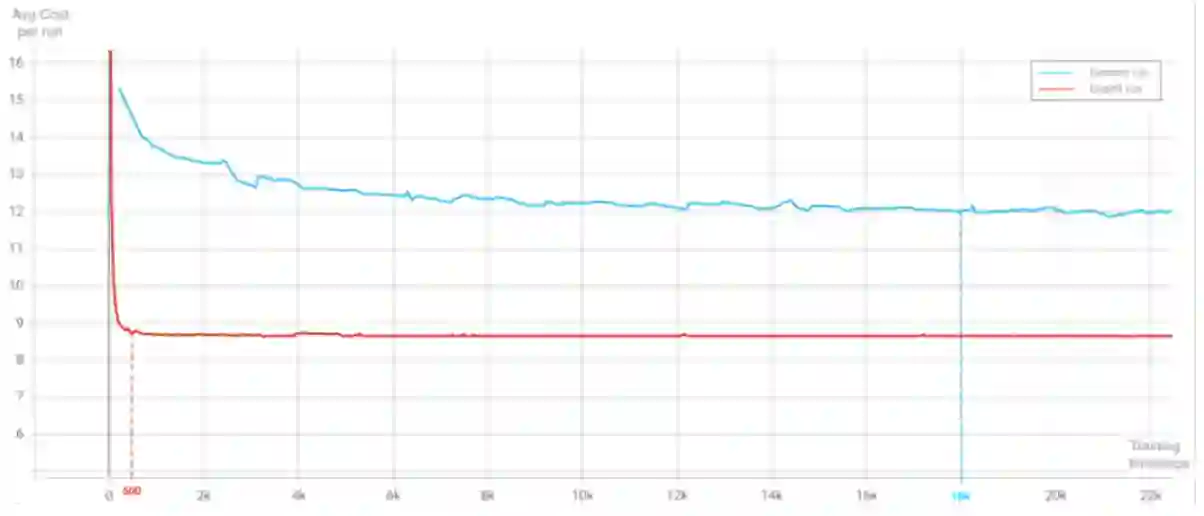
In this paper, we evaluate the use of Reinforcement Learning (RL) to solve a classic combinatorial optimization problem: the Capacitated Vehicle Routing Problem (CVRP). We formalize this problem in the RL framework and compare two of the most promising RL approaches with traditional solving techniques on a set of benchmark instances. We measure the different approaches with the quality of the solution returned and the time required to return it. We found that despite not returning the best solution, the RL approach has many advantages over traditional solvers. First, the versatility of the framework allows the resolution of more complex combinatorial problems. Moreover, instead of trying to solve a specific instance of the problem, the RL algorithm learns the skills required to solve the problem. The trained policy can then quasi instantly provide a solution to an unseen problem without having to solve it from scratch. Finally, the use of trained models makes the RL solver by far the fastest, and therefore make this approach more suited for commercial use where the user experience is paramount. Techniques like Knowledge Transfer can also be used to improve the training efficiency of the algorithm and help solve bigger and more complex problems.
翻译:在本文中,我们评估了使用强化学习(RL)解决经典组合优化问题的经典组合优化问题:机动车辆运行问题(CVRP)的情况。我们将此问题正式纳入RL框架,并在一组基准实例中将两种最有希望的RL方法与传统解决方案技术进行比较。我们用返回解决方案的质量以及归还解决方案所需的时间来衡量不同方法。我们发现,尽管没有回归最佳解决方案,但RL方法比传统解决方案具有许多优势。首先,框架的多功能使得能够解决更为复杂的组合问题。此外,RL算法不是试图解决一个具体的问题,而是学习解决问题所需的技能。经过培训的政策随后可以半瞬间为一个不可见的问题提供解决办法,而不必从零开始解决问题。最后,使用经过培训的模型使RL解答器远是最快的,因此,在用户经验至上更适合商业使用的方法。知识传输等技术也可以用来提高算法的培训效率,帮助解决更大、更复杂的问题。