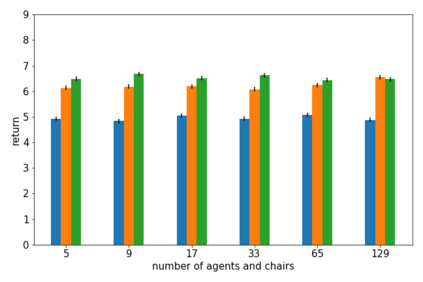
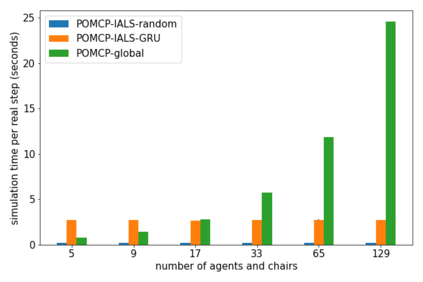
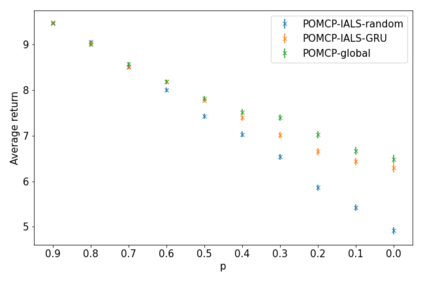
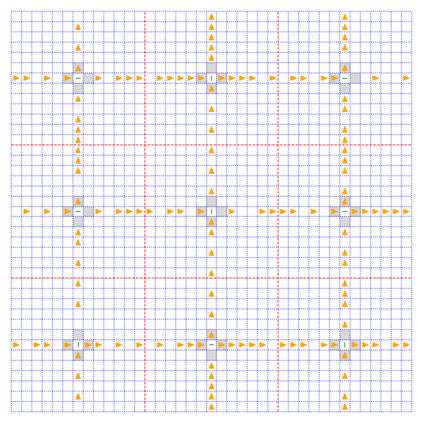
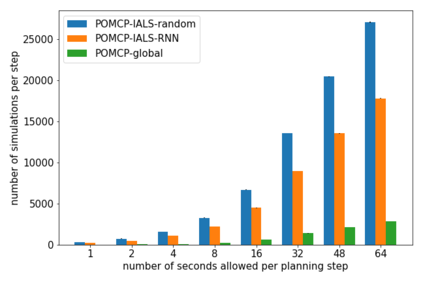
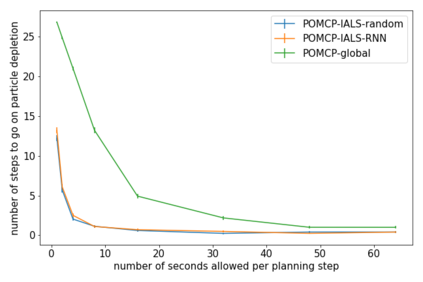
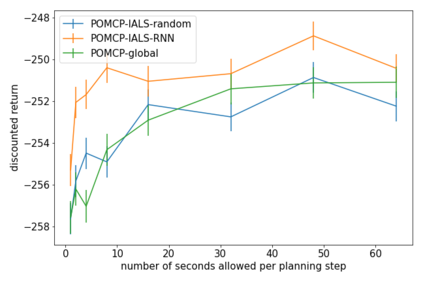
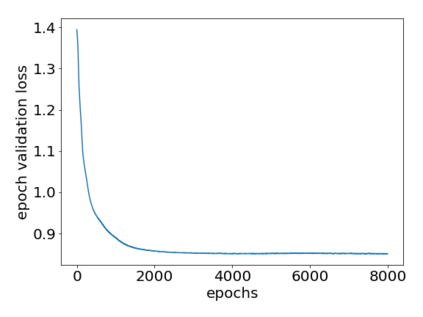
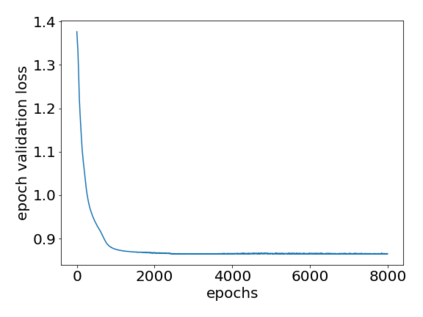
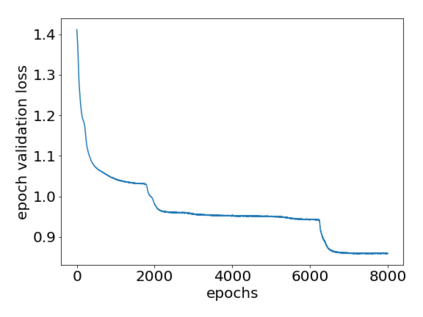
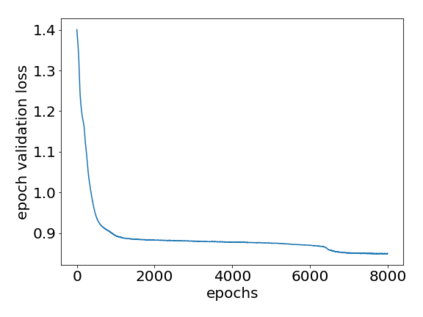
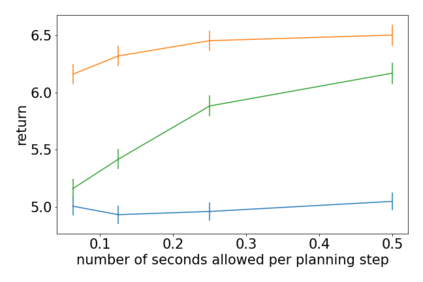
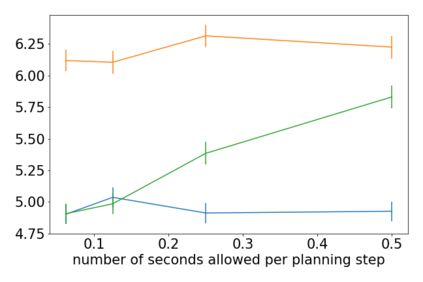
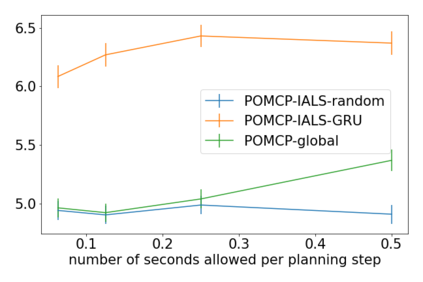
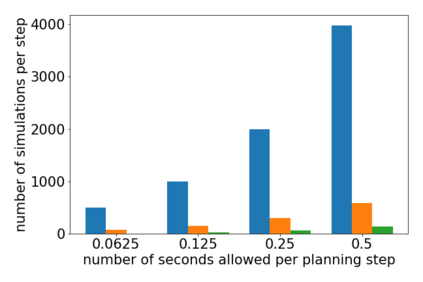
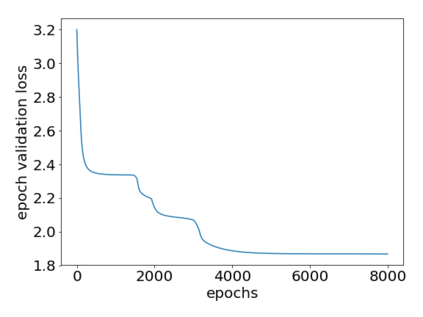
How can we plan efficiently in real time to control an agent in a complex environment that may involve many other agents? While existing sample-based planners have enjoyed empirical success in large POMDPs, their performance heavily relies on a fast simulator. However, real-world scenarios are complex in nature and their simulators are often computationally demanding, which severely limits the performance of online planners. In this work, we propose influence-augmented online planning, a principled method to transform a factored simulator of the entire environment into a local simulator that samples only the state variables that are most relevant to the observation and reward of the planning agent and captures the incoming influence from the rest of the environment using machine learning methods. Our main experimental results show that planning on this less accurate but much faster local simulator with POMCP leads to higher real-time planning performance than planning on the simulator that models the entire environment.
翻译:在可能涉及许多其他代理人的复杂环境中,我们如何能够实时有效地计划控制一个代理人?虽然现有的抽样规划者在大型POMDPs中取得了经验性的成功,但其性能在很大程度上依赖于快速模拟器。然而,现实世界的情景在性质上是复杂的,其模拟器往往在计算上要求很高,这严重限制了在线规划者的业绩。在这项工作中,我们建议采用影响力增强的在线规划,这是将整个环境的因子模拟器转换成一个当地模拟器的一种原则方法,该模拟器只对与规划者观察和奖励最相关的状态变量进行取样,并利用机器学习方法捕捉环境其余部分的影响。我们的主要实验结果显示,在这种不太准确但速度更快的地方模拟器上与POMCP一起进行规划会提高实时规划性,而不是对模拟整个环境的模拟器进行规划。