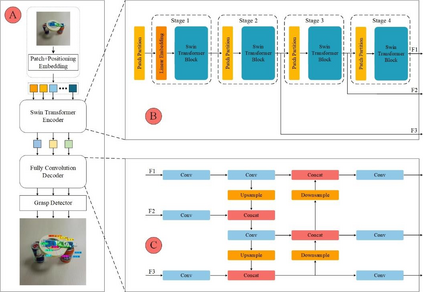
Grasp detection in a cluttered environment is still a great challenge for robots. Currently, the Transformer mechanism has been successfully applied to visual tasks, and its excellent ability of global context information extraction provides a feasible way to improve the performance of robotic grasp detection in cluttered scenes. However, the insufficient inductive bias ability of the original Transformer model requires large-scale datasets training, which is difficult to obtain for grasp detection. In this paper, we propose a grasp detection model based on encoder-decoder structure. The encoder uses a Transformer network to extract global context information. The decoder uses a fully convolutional neural network to improve the inductive bias capability of the model and combine features extracted by the encoder to predict the final grasp configuration. Experiments on the VMRD dataset demonstrate that our model performs much better in overlapping object scenes. Meanwhile, on the Cornell Grasp dataset, our approach achieves an accuracy of 98.1%, which is comparable with state-of-the-art algorithms.
翻译:目前,变异器机制已被成功应用于视觉任务,其全球背景信息提取的极强能力提供了一种可行的方法来改进在杂乱的场景中机器人捕捉探测的性能。然而,原变异器模型的演化偏差能力不足,需要大规模的数据元件训练,难以探测。在本文中,我们提议了一个基于编码器解码器结构的抓取探测模型。编码器使用变异器网络来提取全球背景信息。解码器使用完全卷动的神经网络来提高模型的感应偏差能力,并结合编码器提取的特征来预测最终的抓取配置。VMRD数据集实验表明,我们的模型在重叠的物体场景中表现得更好。同时,在Cornellsp Gra数据集上,我们的方法达到了98.1%的准确率,这与最新算法相当。