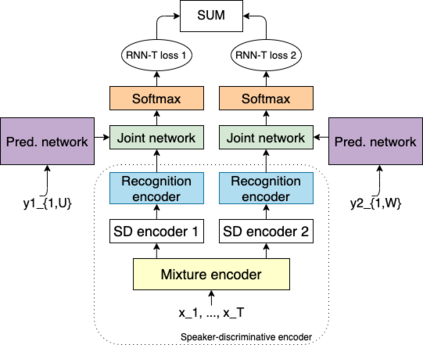
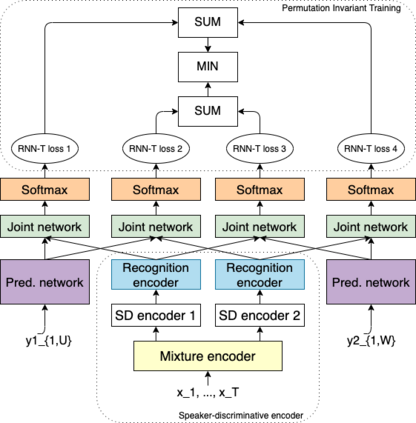
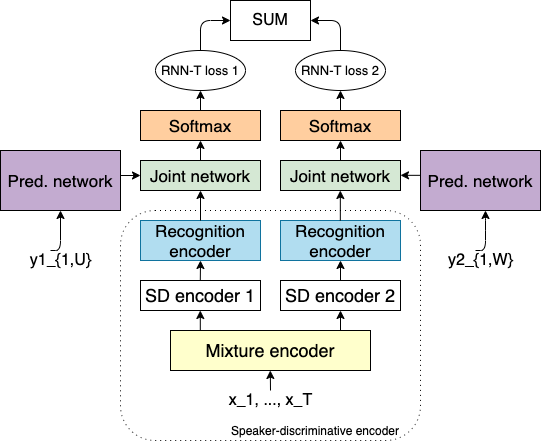
Recent research shows end-to-end ASR systems can recognize overlapped speech from multiple speakers. However, all published works have assumed no latency constraints during inference, which does not hold for most voice assistant interactions. This work focuses on multi-speaker speech recognition based on a recurrent neural network transducer (RNN-T) that has been shown to provide high recognition accuracy at a low latency online recognition regime. We investigate two approaches to multi-speaker model training of the RNN-T: deterministic output-target assignment and permutation invariant training. We show that guiding separation with speaker order labels in the former case enhances the high-level speaker tracking capability of RNN-T. Apart from that, with multistyle training on single- and multi-speaker utterances, the resulting models gain robustness against ambiguous numbers of speakers during inference. Our best model achieves a WER of 10.2% on simulated 2-speaker LibriSpeech data, which is competitive with the previously reported state-of-the-art nonstreaming model (10.3%), while the proposed model could be directly applied for streaming applications.
翻译:最近的研究显示,终端到终端的ASR系统可以识别多个发言者的重复发言。然而,所有出版的作品在推断期间都假定没有长期限制,而这对大多数语音助理的相互作用没有影响。这项工作侧重于基于经常性神经网络传输器(RNN-T)的多声语音识别,这显示在低悬浮在线识别制度中提供了高度的识别精度。我们调查了多声模式培训RNN-T的两种方法:确定性输出目标分配和变异性培训。我们显示,在前一种情况下,与扬声器标签分开的指导会增强RNNN-T的高级语音跟踪能力。除此之外,通过关于单声器和多声器语音的多语调培训,由此形成的模型对低静音量的在线识别系统具有很强的识别力。我们的最佳模型在模拟的2声器LibriSpeech数据上取得了10.2%的WER,该模型与先前报告的状态非流式应用程序具有竞争力(10.3%),而拟议的模型可以直接用于流式应用。