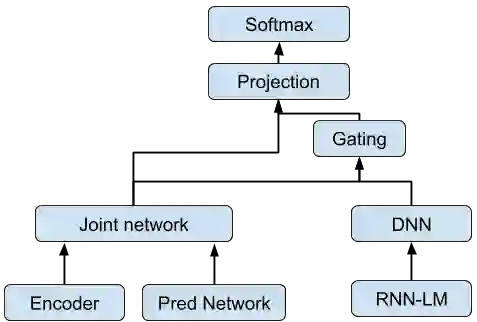
Streaming processing of speech audio is required for many contemporary practical speech recognition tasks. Even with the large corpora of manually transcribed speech data available today, it is impossible for such corpora to cover adequately the long tail of linguistic content that's important for tasks such as open-ended dictation and voice search. We seek to address both the streaming and the tail recognition challenges by using a language model (LM) trained on unpaired text data to enhance the end-to-end (E2E) model. We extend shallow fusion and cold fusion approaches to streaming Recurrent Neural Network Transducer (RNNT), and also propose two new competitive fusion approaches that further enhance the RNNT architecture. Our results on multiple languages with varying training set sizes show that these fusion methods improve streaming RNNT performance through introducing extra linguistic features. Cold fusion works consistently better on streaming RNNT with up to a 8.5% WER improvement.
翻译:许多当代实际语音识别任务都需要对语音音频进行分流处理。 即便如今手动转录语音数据数量庞大,这种公司也不可能充分覆盖对开放式听写和语音搜索等任务至关重要的语言内容的长尾尾。 我们试图通过使用语言模型(LM),通过使用受过未调译文本数据培训的语言模型(LM)来应对流流和尾部识别挑战,以加强端到端模式(E2E)。 我们将浅质聚和冷聚方法推广到流经常性神经网络转换器(RNNNT),并提议两种新的竞争性聚合方法,以进一步加强RNNT结构。 我们关于多种语言(不同培训尺寸)的结果显示,这些融合方法通过引入额外的语言特征来改进流出RNNT的性能。 冷聚能在流中持续地改进RNNT,使流到8.5%的WER改进。