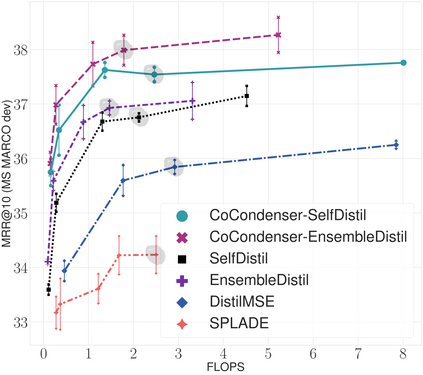
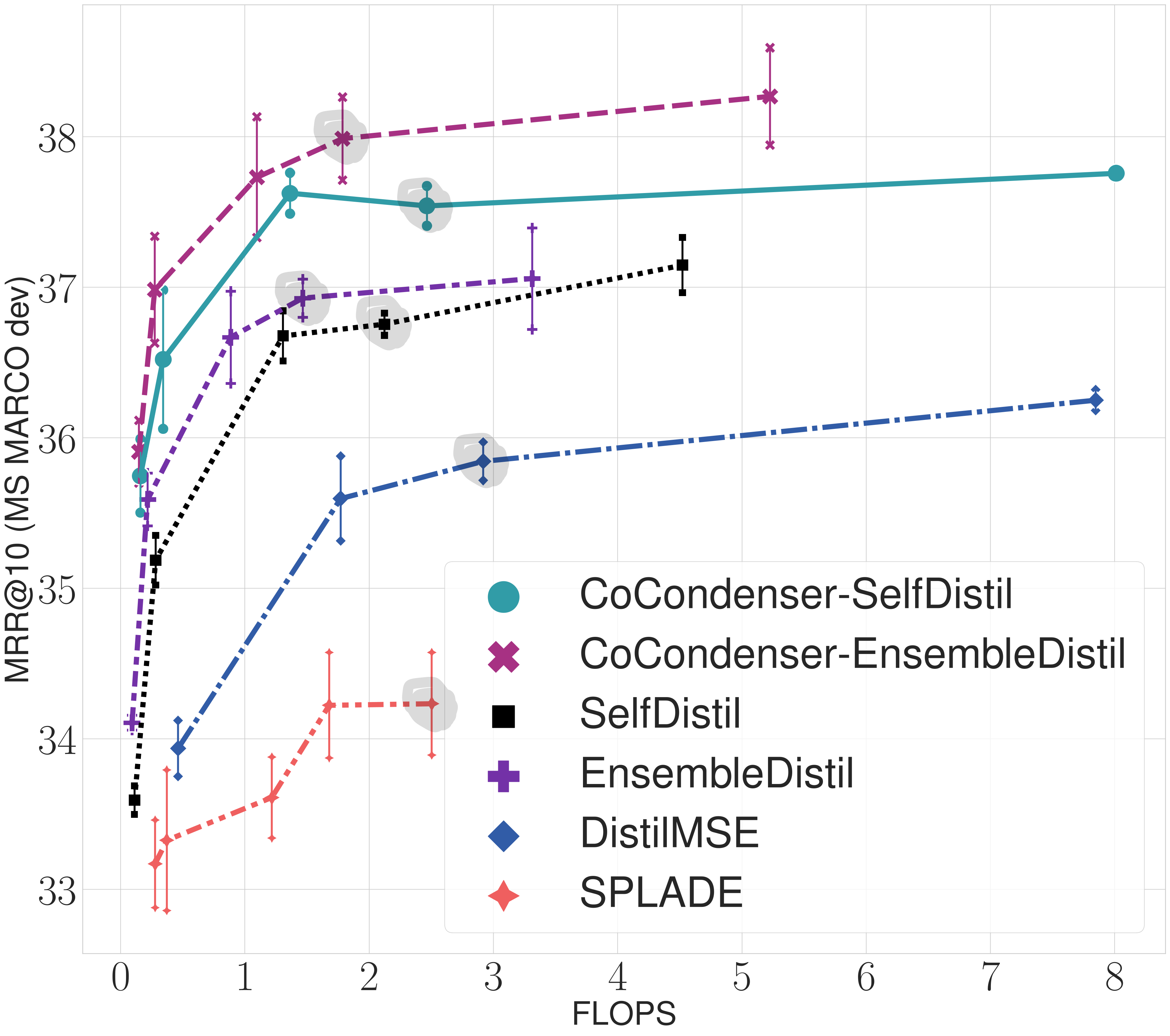
Neural retrievers based on dense representations combined with Approximate Nearest Neighbors search have recently received a lot of attention, owing their success to distillation and/or better sampling of examples for training -- while still relying on the same backbone architecture. In the meantime, sparse representation learning fueled by traditional inverted indexing techniques has seen a growing interest, inheriting from desirable IR priors such as explicit lexical matching. While some architectural variants have been proposed, a lesser effort has been put in the training of such models. In this work, we build on SPLADE -- a sparse expansion-based retriever -- and show to which extent it is able to benefit from the same training improvements as dense models, by studying the effect of distillation, hard-negative mining as well as the Pre-trained Language Model initialization. We furthermore study the link between effectiveness and efficiency, on in-domain and zero-shot settings, leading to state-of-the-art results in both scenarios for sufficiently expressive models.
翻译:根据密集表象以及近距离近邻搜索而形成的神经检索器最近受到了很多关注,因为它们成功地进行了蒸馏和(或)更好的培训范例抽样,同时仍然依靠同样的主干结构。与此同时,传统反向指数化技术所推动的鲜为代表学习越来越受关注,继承了理想的IR的先期经验,如明确的词汇匹配。虽然提出了一些建筑变体,但在培训这些模型方面却投入了较少的努力。在这项工作中,我们利用了很少的扩展检索器,通过研究蒸馏、硬反向采矿以及预先培训的语言模型初始化的效果,展示了它在多大程度上能够从密集模型的同样的培训改进中受益。我们进一步研究了在主干区和零点环境的效力和效率之间的联系,导致在两种情景中都取得了最先进的结果,以充分表达模型为目的。