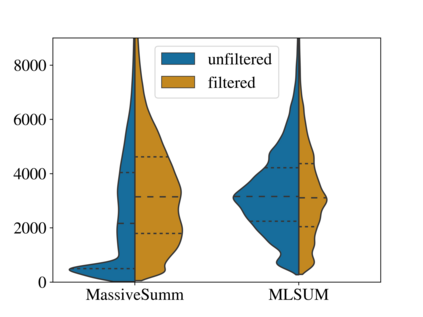
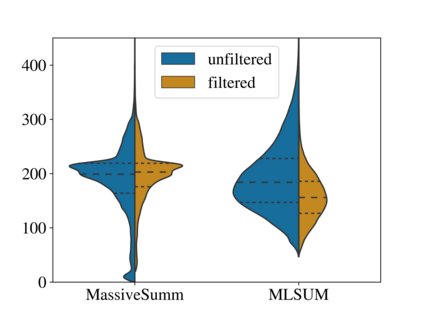
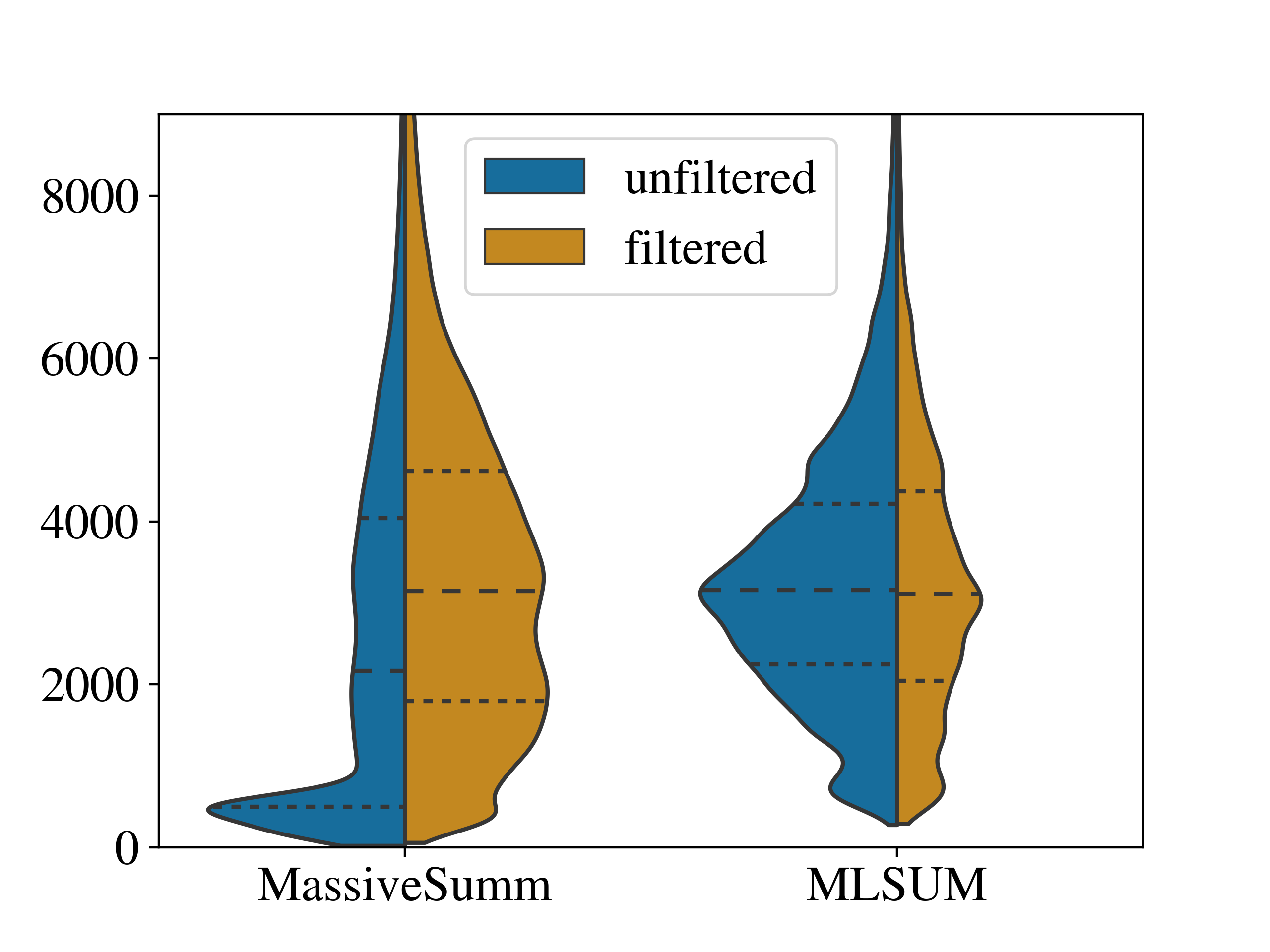
With recent advancements in the area of Natural Language Processing, the focus is slowly shifting from a purely English-centric view towards more language-specific solutions, including German. Especially practical for businesses to analyze their growing amount of textual data are text summarization systems, which transform long input documents into compressed and more digestible summary texts. In this work, we assess the particular landscape of German abstractive text summarization and investigate the reasons why practically useful solutions for abstractive text summarization are still absent in industry. Our focus is two-fold, analyzing a) training resources, and b) publicly available summarization systems. We are able to show that popular existing datasets exhibit crucial flaws in their assumptions about the original sources, which frequently leads to detrimental effects on system generalization and evaluation biases. We confirm that for the most popular training dataset, MLSUM, over 50% of the training set is unsuitable for abstractive summarization purposes. Furthermore, available systems frequently fail to compare to simple baselines, and ignore more effective and efficient extractive summarization approaches. We attribute poor evaluation quality to a variety of different factors, which are investigated in more detail in this work: A lack of qualitative (and diverse) gold data considered for training, understudied (and untreated) positional biases in some of the existing datasets, and the lack of easily accessible and streamlined pre-processing strategies or analysis tools. We provide a comprehensive assessment of available models on the cleaned datasets, and find that this can lead to a reduction of more than 20 ROUGE-1 points during evaluation. The code for dataset filtering and reproducing results can be found online at https://github.com/dennlinger/summaries
翻译:随着《自然语言处理》领域最近的进展,重点正在缓慢地从纯粹以英语为中心的观点转向更具体语言的解决方案,包括德语。特别是,对于企业来说,分析其不断增加的文本数据数量的实用系统是文本总化系统,它将长的输入文件转换成压缩和更加可消化的简要文本。在这项工作中,我们评估了德国抽象文本总化的特定景观,并调查了为什么工业界仍然缺乏抽象文本总化的实际有用解决方案的原因。我们的重点有两个方面,即分析(a)培训资源,和(b)公开提供的总和系统。我们能够表明,流行的现有数据集在对原始来源的假设中显示出严重的缺陷,这经常导致对系统一般化和评价偏差产生有害影响。我们确认,对于最受欢迎的培训数据集,即MLSUM,50%以上的培训数据集不适合抽象的概括化目的。此外,现有系统往往无法与简单的基线进行比较,忽视更高效和高效的提取总和可获取的方法。我们把评估质量差归咎于各种因素,而目前对在线数据结构进行更深入的调查,在这项工作中,缺乏质量和数据分析中,缺乏一些对现有数据分析的准确性,缺乏数据分析。