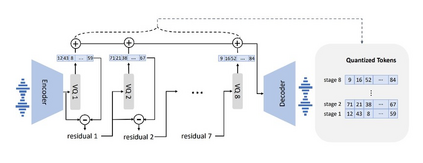
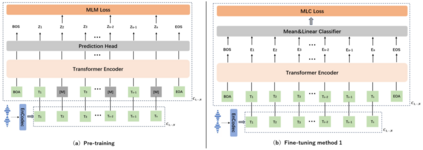
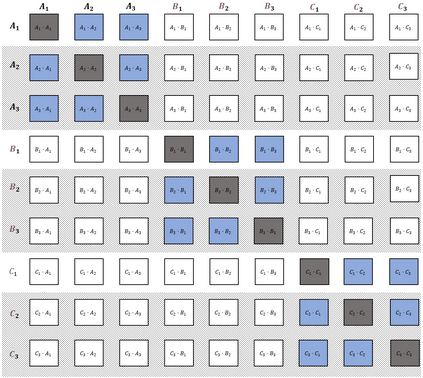
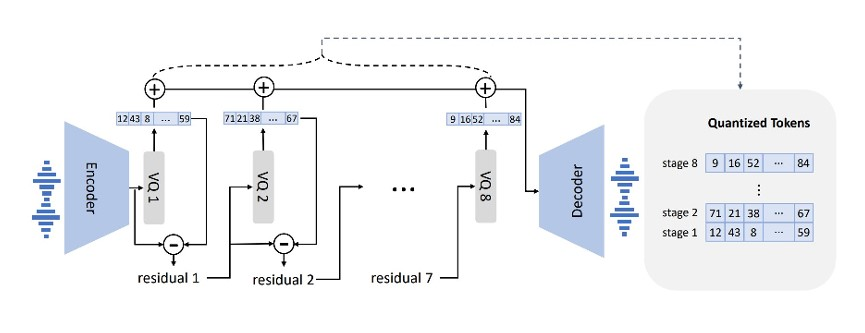
We propose a method named AudioFormer, which learns audio feature representations through the acquisition of discrete acoustic codes and subsequently fine-tunes them for audio classification tasks. Initially, we introduce a novel perspective by considering the audio classification task as a form of natural language understanding (NLU). Leveraging an existing neural audio codec model, we generate discrete acoustic codes and utilize them to train a masked language model (MLM), thereby obtaining audio feature representations. Furthermore, we pioneer the integration of a \textbf{M}ulti-\textbf{P}ositive sample \textbf{C}ontrastive (MPC) learning approach. This method enables the learning of joint representations among multiple discrete acoustic codes within the same audio input. In our experiments, we treat discrete acoustic codes as textual data and train a masked language model using a cloze-like methodology, ultimately deriving high-quality audio representations. Notably, the MPC learning technique effectively captures collaborative representations among distinct positive samples. Our research outcomes demonstrate that AudioFormer attains significantly improved performance compared to prevailing monomodal audio classification models across multiple datasets, and even outperforms audio-visual multimodal classification models on select datasets. Specifically, our approach achieves remarkable results on datasets including AudioSet (2M, 20K), and FSD50K, with performance scores of 53.9, 45.1, and 65.6, respectively. We have openly shared both the code and models: \url{https://github.com/LZH-0225/AudioFormer.git}.
翻译:暂无翻译