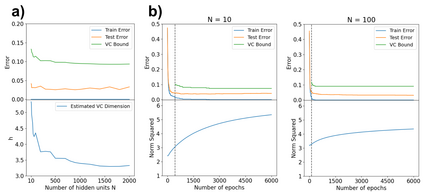
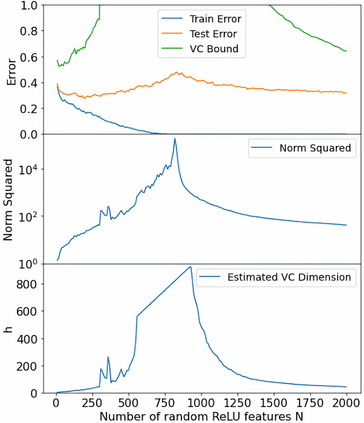
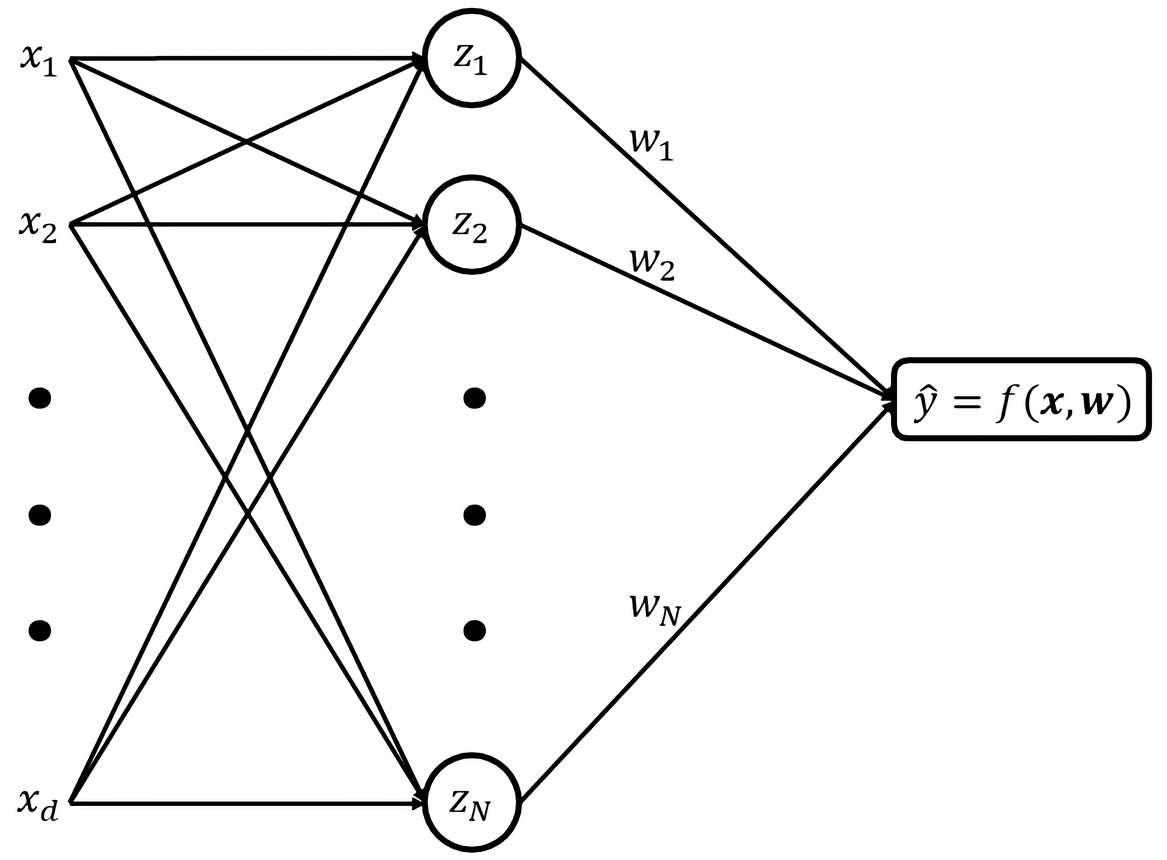
There has been growing interest in generalization performance of large multilayer neural networks that can be trained to achieve zero training error, while generalizing well on test data. This regime is known as 'second descent' and it appears to contradict the conventional view that optimal model complexity should reflect an optimal balance between underfitting and overfitting, i.e., the bias-variance trade-off. This paper presents a VC-theoretical analysis of double descent and shows that it can be fully explained by classical VC-generalization bounds. We illustrate an application of analytic VC-bounds for modeling double descent for classification problems, using empirical results for several learning methods, such as SVM, Least Squares, and Multilayer Perceptron classifiers. In addition, we discuss several reasons for the misinterpretation of VC-theoretical results in Deep Learning community.
翻译:人们日益关注大型多层神经网络的普及性能,这些网络可以被训练达到零培训错误,同时对测试数据进行全面推广。这个制度被称为“第二位 ”, 并且似乎与以下传统观点相矛盾,即最佳模型复杂性应反映不适应和超适应之间的最佳平衡,即偏差取舍。本文对双位血缘进行了VC理论分析,并表明它可以用传统的VC一般化界限来充分解释。我们用SVM、最低广场和多层 Perceptron分类方法的经验结果来示范分类问题的双位血缘。此外,我们讨论了深层学习界对VC理论结果的曲解的若干原因。