
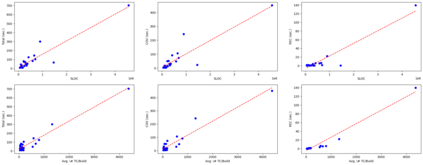
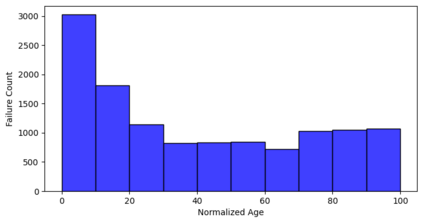
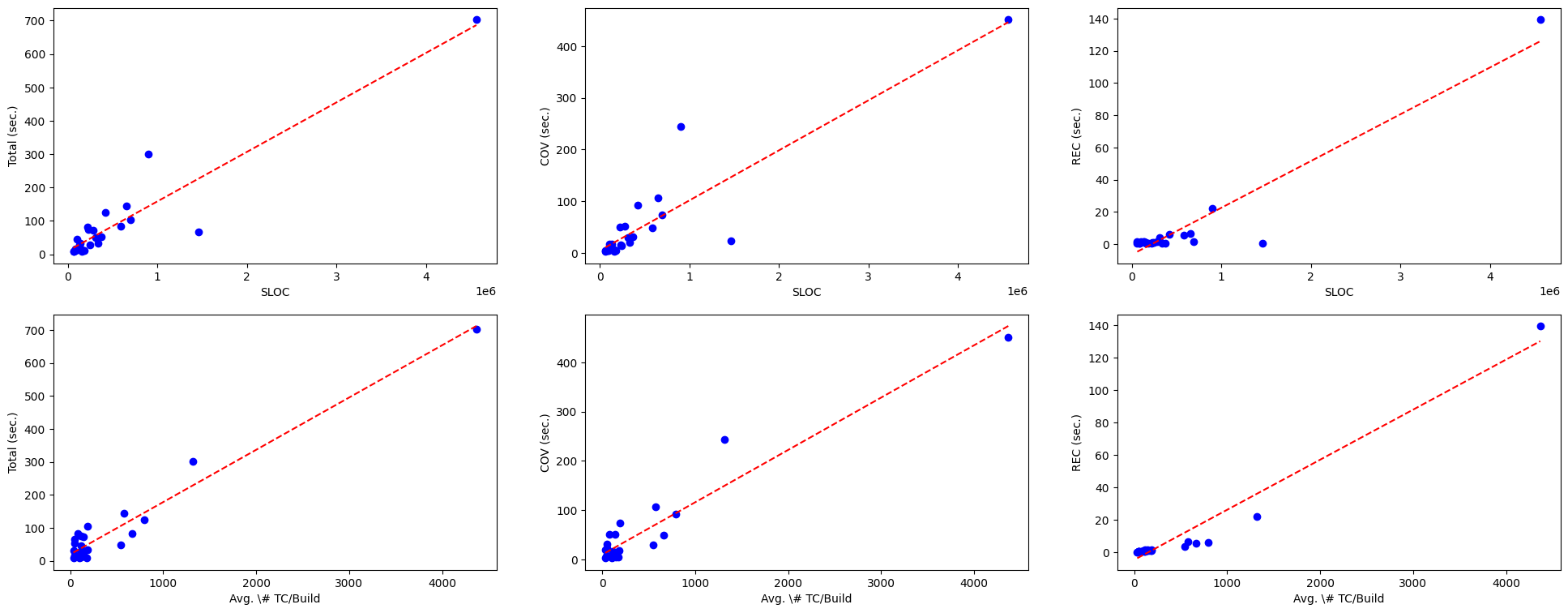
Continuous Integration (CI) requires efficient regression testing to ensure software quality without significantly delaying its CI builds. This warrants the need for techniques to reduce regression testing time, such as Test Case Prioritization (TCP) techniques that prioritize the execution of test cases to detect faults as early as possible. Many recent TCP studies employ various Machine Learning (ML) techniques to deal with the dynamic and complex nature of CI. However, most of them use a limited number of features for training ML models and evaluate the models on subjects for which the application of TCP makes little practical sense, due to their small regression testing time and low number of failed builds. In this work, we first define, at a conceptual level, a data model that captures data sources and their relations in a typical CI environment. Second, based on this data model, we define a comprehensive set of features that covers all features previously used by related studies. Third, we develop methods and tools to collect the defined features for 25 open-source software systems with enough failed builds and whose regression testing takes at least five minutes. Fourth, relying on the collected dataset containing a comprehensive feature set, we answer four research questions concerning data collection time, the accuracy of ML-based TCP, the impact of the features on accuracy, the decay of ML-based TCP models over time, and the trade-off between data collection time and the accuracy of ML-based TCP techniques.
翻译:连续整合(CI) 需要高效的回归测试,以确保软件质量,而不会大大拖延其CI的构建。这就需要减少回归测试时间的技术,例如测试案例优先排序(TCP)技术,优先执行测试案例,以便尽早发现故障。最近许多TCP研究采用各种机器学习(ML)技术,处理CI的动态和复杂性质。然而,大多数TCP在培训ML模型方面使用数量有限的特点,并评估应用TCP几乎没有实际意义的主题模型,因为TCP的回归测试时间很小,而且失败的建筑数量较少。在这项工作中,我们首先在概念层面确定一种数据模型,在典型的CI环境中记录数据来源及其关系。第二,我们根据这一数据模型,确定一套综合特征,涵盖CI的动态和复杂性质。第三,我们开发了方法和工具,收集25个基于足够失败的开放源软件系统的既定特征,其回归测试至少需要5分钟。第四,依靠收集的综合特征集,我们回答关于TCP的数据收集时间、MCP的准确性和ML的ML模型的影响、ML的ML的精确性、T-CP的ML的MCP模型的数据收集、T-时间特征之间的四个研究问题。
相关内容

Source: Apple - iOS 8


