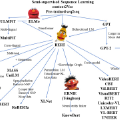
The exponential growth of biomedical texts such as biomedical literature and electronic health records (EHRs), provides a big challenge for clinicians and researchers to access clinical information efficiently. To address the problem, biomedical text summarization has been proposed to support clinical information retrieval and management, aiming at generating concise summaries that distill key information from single or multiple biomedical documents. In recent years, pre-trained language models (PLMs) have been the de facto standard of various natural language processing tasks in the general domain. Most recently, PLMs have been further investigated in the biomedical field and brought new insights into the biomedical text summarization task. In this paper, we systematically summarize recent advances that explore PLMs for biomedical text summarization, to help understand recent progress, challenges, and future directions. We categorize PLMs-based approaches according to how they utilize PLMs and what PLMs they use. We then review available datasets, recent approaches and evaluation metrics of the task. We finally discuss existing challenges and promising future directions. To facilitate the research community, we line up open resources including available datasets, recent approaches, codes, evaluation metrics, and the leaderboard in a public project: https://github.com/KenZLuo/Biomedical-Text-Summarization-Survey/tree/master.
翻译:近年来,生物医学文本的指数增长,如生物医学文献和电子健康记录 (EHR),为临床医生和研究人员提供了高效访问临床信息的巨大挑战。为了解决这个问题,生物医学文本摘要被提出来支持临床信息检索和管理,旨在生成简要概述,从单个或多个生物医学文档中提取关键信息。近年来,预训练语言模型 (PLMs) 已成为各种通用领域自然语言处理任务的事实标准。最近,PLMs在生物医学领域进一步研究,并为生物医学文本摘要任务带来了新的见解。在本文中,我们系统概述了最新的使用PLMs进行生物医学文本摘要的研究,以帮助理解最近的进展、挑战和未来方向。我们根据它们如何利用PLMs和使用什么PLMs将基于PLMs的方法分类。我们然后回顾可用数据集、最近的方法和评估指标。最后,我们讨论现有的挑战和有前途的未来方向。为了方便研究社区,我们在一个公共项目中列出了开放资源,包括可用的数据集、最近的方法、代码、评估指标和排行榜: https://github.com/KenZLuo/biomedical-text-summarization-survey/tree/master.