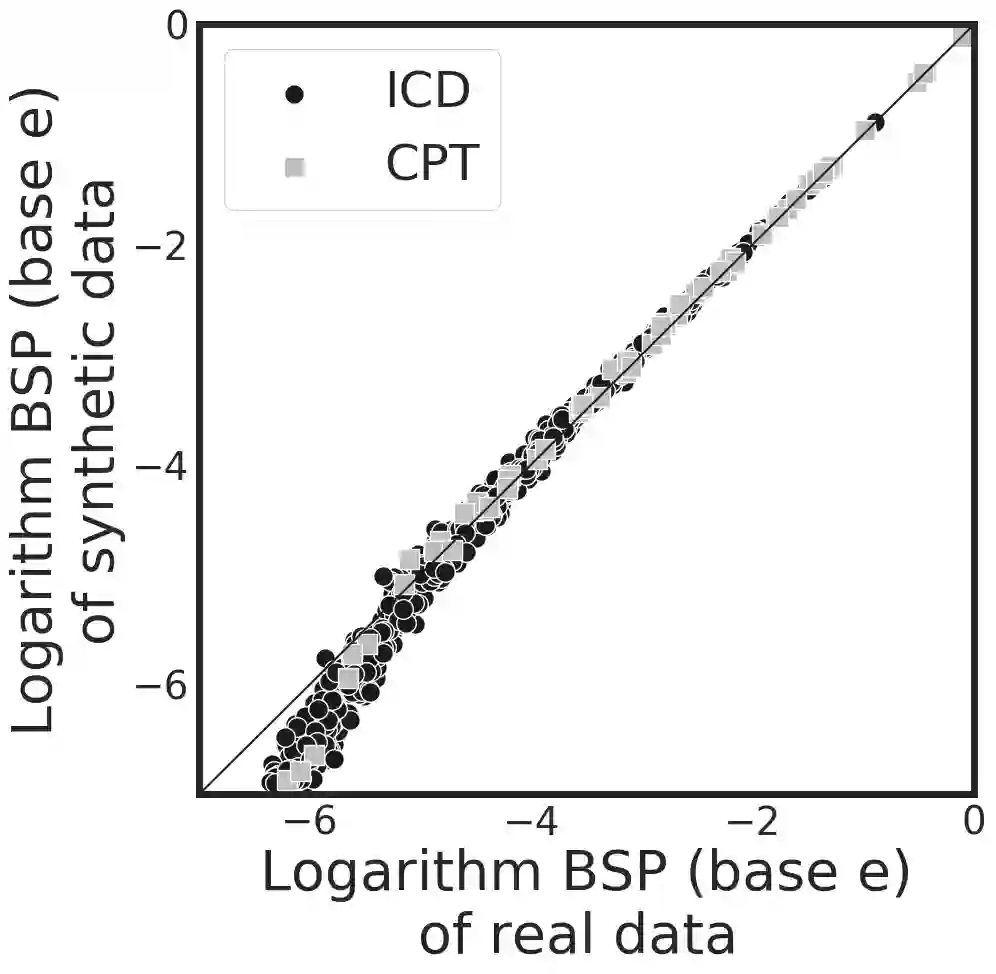
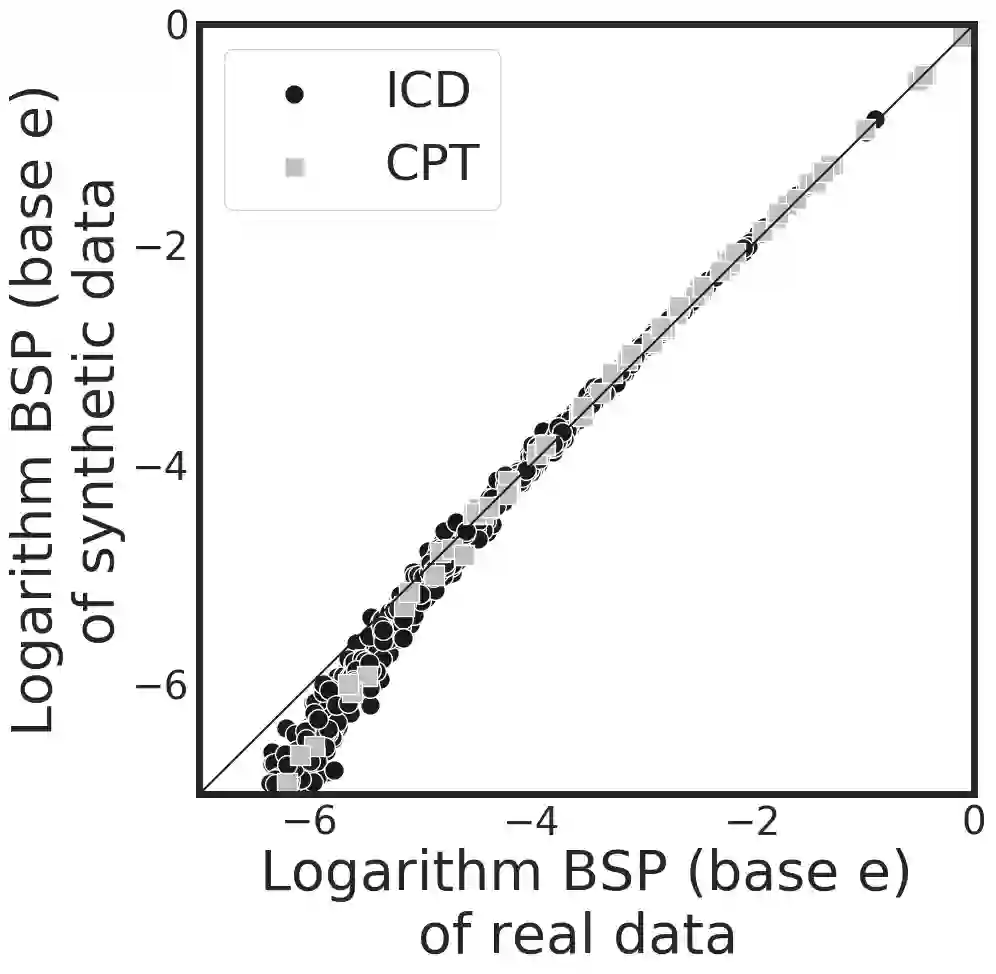
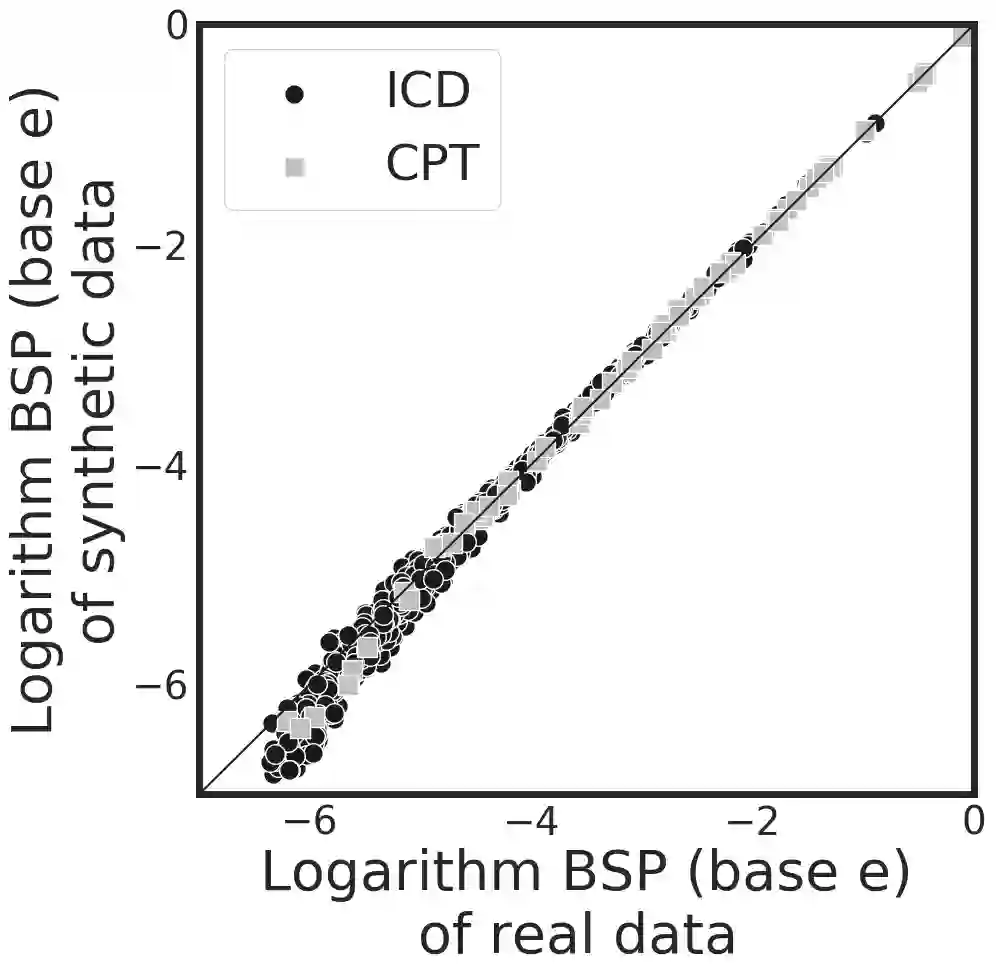
Sharing electronic health records (EHRs) on a large scale may lead to privacy intrusions. Recent research has shown that risks may be mitigated by simulating EHRs through generative adversarial network (GAN) frameworks. Yet the methods developed to date are limited because they 1) focus on generating data of a single type (e.g., diagnosis codes), neglecting other data types (e.g., demographics, procedures or vital signs) and 2) do not represent constraints between features. In this paper, we introduce a method to simulate EHRs composed of multiple data types by 1) refining the GAN model, 2) accounting for feature constraints, and 3) incorporating utility measures for such generation tasks. The findings over 770K EHRs from Vanderbilt University Medical Center demonstrate that our model achieved higher data utilities in retaining the basic statistics, interdimensional correlation, structural properties and frequent association rules from real data. Importantly, these were done without sacrificing privacy.
翻译:最近的研究表明,通过基因对抗网络(GAN)框架模拟EHR可以减轻风险,然而,迄今为止制定的方法是有限的,因为它们1 侧重于生成单一类型的数据(例如诊断代码),忽视其他类型的数据(例如人口、程序或生命迹象)和2,并不代表各种特征之间的制约;在本文件中,我们采用了一种方法来模拟由多种数据类型组成的EHR(1) 改进GAN模型,2 说明特征制约,3) 纳入这种生成任务的实用性措施。 Vanderbilt大学医疗中心的770K EHR的调查结果表明,我们的模型在保留基本统计数据、维维系相关性、结构属性和从真实数据中经常使用关联规则方面实现了更高的数据效用。重要的是,这些是在不牺牲隐私的情况下完成的。