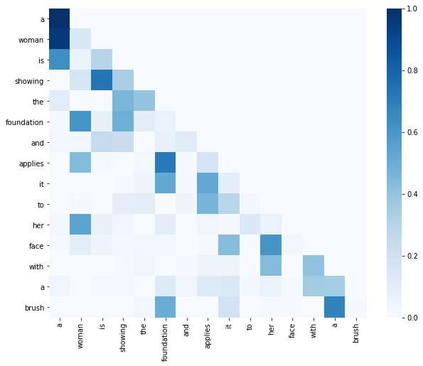
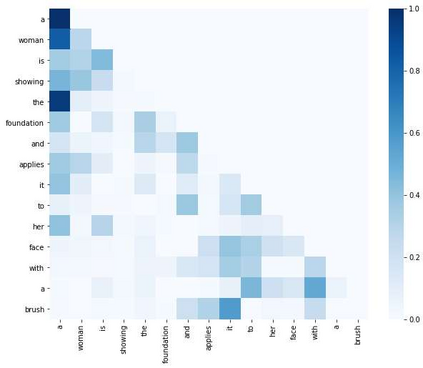
The task of video-based commonsense captioning aims to generate event-wise captions and meanwhile provide multiple commonsense descriptions (e.g., attribute, effect and intention) about the underlying event in the video. Prior works explore the commonsense captions by using separate networks for different commonsense types, which is time-consuming and lacks mining the interaction of different commonsense. In this paper, we propose a Hybrid Reasoning Network (HybridNet) to endow the neural networks with the capability of semantic-level reasoning and word-level reasoning. Firstly, we develop multi-commonsense learning for semantic-level reasoning by jointly training different commonsense types in a unified network, which encourages the interaction between the clues of multiple commonsense descriptions, event-wise captions and videos. Then, there are two steps to achieve the word-level reasoning: (1) a memory module records the history predicted sequence from the previous generation processes; (2) a memory-routed multi-head attention (MMHA) module updates the word-level attention maps by incorporating the history information from the memory module into the transformer decoder for word-level reasoning. Moreover, the multimodal features are used to make full use of diverse knowledge for commonsense reasoning. Experiments and abundant analysis on the large-scale Video-to-Commonsense benchmark show that our HybridNet achieves state-of-the-art performance compared with other methods.
翻译:在本文中,我们提议建立一个混合理性网络(HybridNet),使神经网络具备语义级推理和字级推理的能力。首先,我们通过在一个统一的网络中联合培训不同的常识类型,通过使用不同常识类型的不同网络,探索常识性说明,这是耗时且缺乏不同常识互动的不同的网络。然后,我们提出一个混合理性网络(HybridNet),使神经网络具备语义级推理和字级推理的能力。首先,我们通过在一个统一的网络中联合培训不同的常识类型,鼓励多种常识描述、事件性说明和视频的线索之间的互动。然后,有两个步骤可以实现字级推理:(1) 记忆模块记录前一代进程的历史预测序列;(2) 记忆式多头目网络模块(MMMAHA),通过将历史信息从存储模块到语义级推理推理学级推理学,从而将历史信息从存储模块到不同常识级推理学级推理学,而将我们通用的常识级推理学级推理学级推理学级推算法用于大比例。