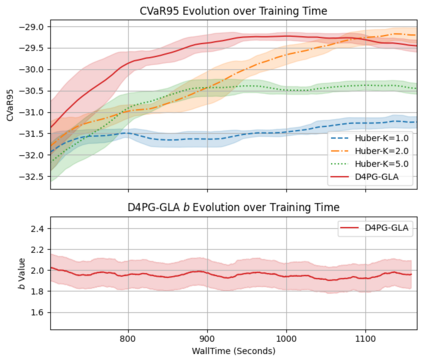
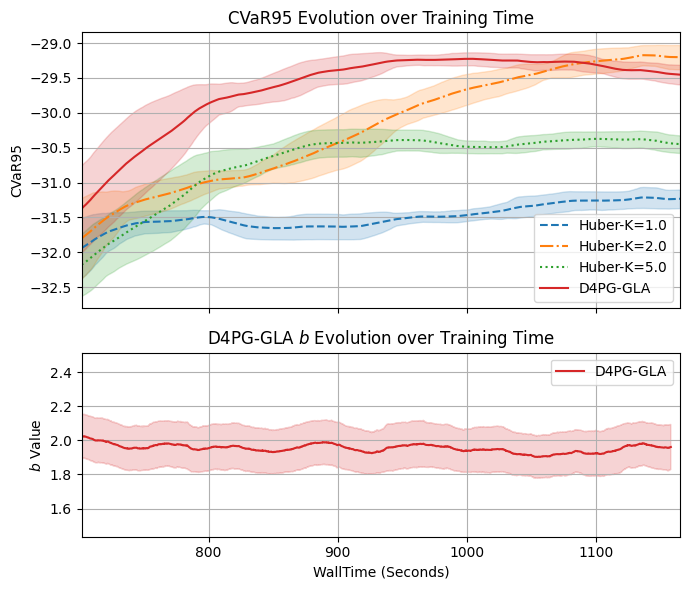
Distributional Reinforcement Learning (RL) estimates return distribution mainly by learning quantile values via minimizing the quantile Huber loss function, entailing a threshold parameter often selected heuristically or via hyperparameter search, which may not generalize well and can be suboptimal. This paper introduces a generalized quantile Huber loss function derived from Wasserstein distance (WD) calculation between Gaussian distributions, capturing noise in predicted (current) and target (Bellman-updated) quantile values. Compared to the classical quantile Huber loss, this innovative loss function enhances robustness against outliers. Notably, the classical Huber loss function can be seen as an approximation of our proposed loss, enabling parameter adjustment by approximating the amount of noise in the data during the learning process. Empirical tests on Atari games, a common application in distributional RL, and a recent hedging strategy using distributional RL, validate the effectiveness of our proposed loss function and its potential for parameter adjustments in distributional RL.
翻译:暂无翻译