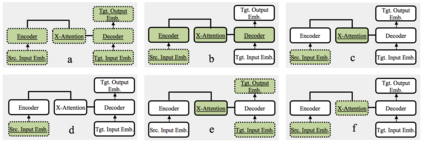
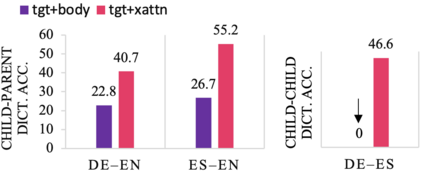
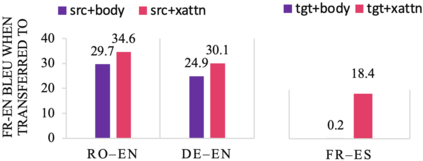
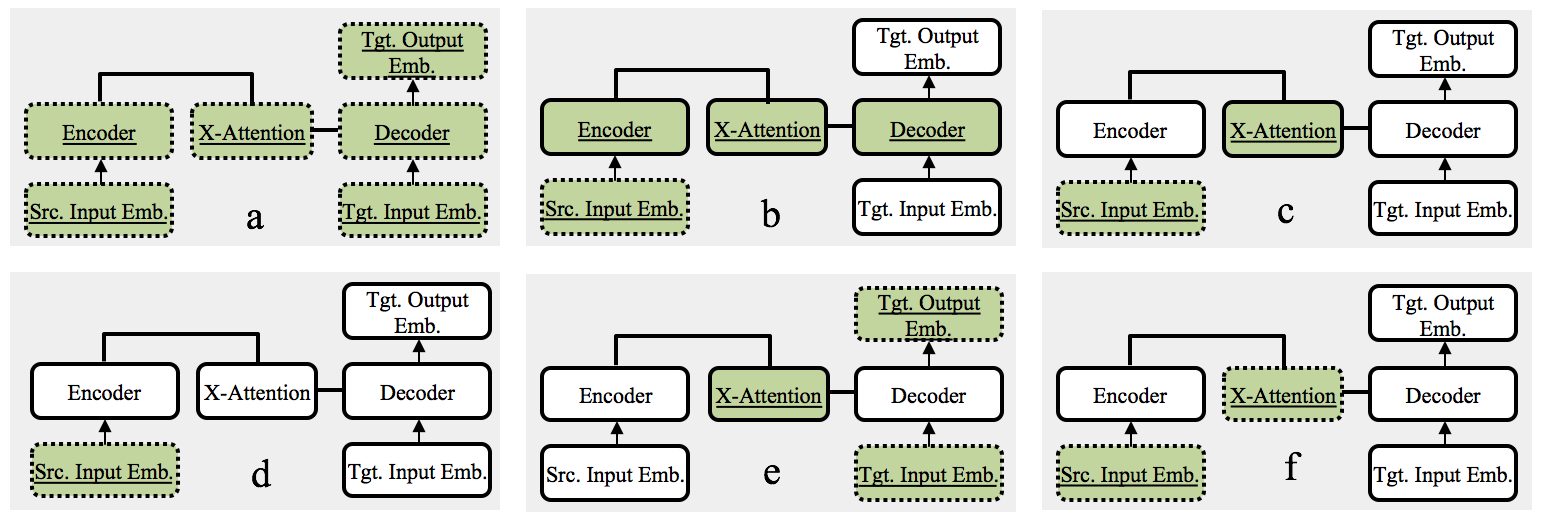
We study the power of cross-attention in the Transformer architecture within the context of transfer learning for machine translation, and extend the findings of studies into cross-attention when training from scratch. We conduct a series of experiments through fine-tuning a translation model on data where either the source or target language has changed. These experiments reveal that fine-tuning only the cross-attention parameters is nearly as effective as fine-tuning all parameters (i.e., the entire translation model). We provide insights into why this is the case and observe that limiting fine-tuning in this manner yields cross-lingually aligned embeddings. The implications of this finding for researchers and practitioners include a mitigation of catastrophic forgetting, the potential for zero-shot translation, and the ability to extend machine translation models to several new language pairs with reduced parameter storage overhead.
翻译:我们从头到尾地研究变换器结构中交叉注意的动力,从机器翻译转移学习的角度研究相互注意的动力,并将研究结果推广到培训过程中的交叉注意。我们通过微调源语言或目标语言发生变化的数据翻译模型进行了一系列实验。这些实验显示,微调仅调整交叉注意参数与微调所有参数(即整个翻译模型)一样有效。我们深入了解了为什么情况如此,并观察到以这种方式限制微调会产生跨语言的嵌入。这一发现对研究人员和从业人员的影响包括减轻灾难性的遗忘、零速翻译的可能性以及将机器翻译模型推广到几个参数存储管理减少的新语言对口的能力。