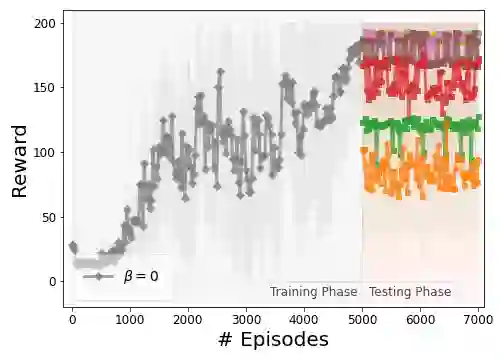
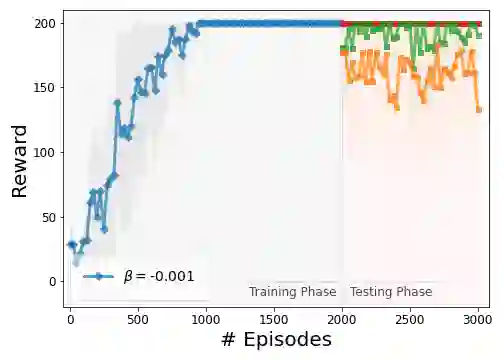
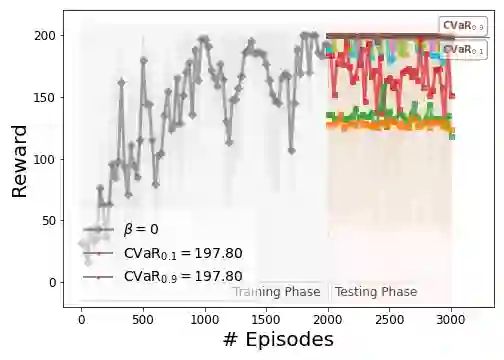
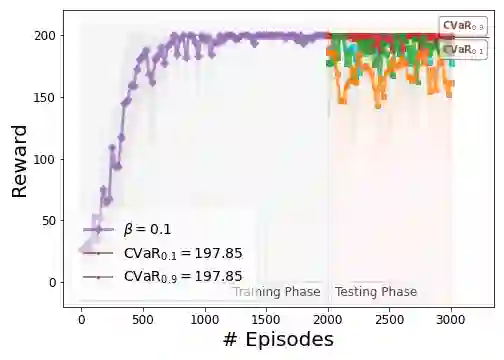
While reinforcement learning has shown experimental success in a number of applications, it is known to be sensitive to noise and perturbations in the parameters of the system, leading to high variance in the total reward amongst different episodes on slightly different environments. To introduce robustness, as well as sample efficiency, risk-sensitive reinforcement learning methods are being thoroughly studied. In this work, we provide a definition of robust reinforcement learning policies and formulate a risk-sensitive reinforcement learning problem to approximate them, by solving an optimization problem with respect to a modified objective based on exponential criteria. In particular, we study a model-free risk-sensitive variation of the widely-used Monte Carlo Policy Gradient algorithm, and introduce a novel risk-sensitive online Actor-Critic algorithm based on solving a multiplicative Bellman equation using stochastic approximation updates. Analytical results suggest that the use of exponential criteria generalizes commonly used ad-hoc regularization approaches, improves sample efficiency, and introduces robustness with respect to perturbations in the model parameters and the environment. The implementation, performance, and robustness properties of the proposed methods are evaluated in simulated experiments.
翻译:暂无翻译