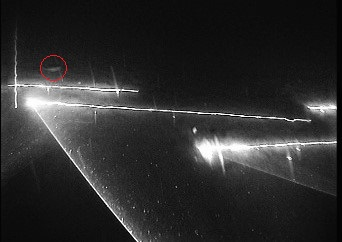
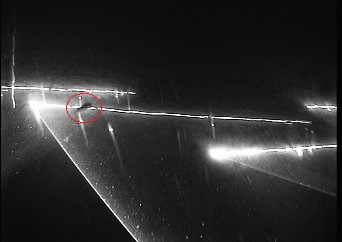
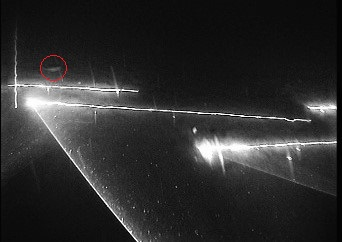
This paper considers the automatic classification of herding behavior in the cluttered low-visibility environment that typically surrounds towed fishing gear. The paper compares three convolutional and attention-based deep action recognition network architectures trained end-to-end on a small set of video sequences captured by a remotely controlled camera and classified by an expert in fishing technology. The sequences depict a scene in front of a fishing trawl where the conventional herding mechanism has been replaced by directed laser light. The goal is to detect the presence of a fish in the sequence and classify whether or not the fish reacts to the lasers. A two-stream CNN model, a CNN-transformer hybrid, and a pure transformer model were trained end-to-end to achieve 63%, 54%, and 60% 10-fold classification accuracy on the three-class task when compared to the human expert. Inspection of the activation maps learned by the three networks raises questions about the attributes of the sequences the models may be learning, specifically whether changes in viewpoint introduced by human camera operators that affect the position of laser lines in the video frames may interfere with the classification. This underlines the importance of careful experimental design when capturing scientific data for automatic end-to-end evaluation and the usefulness of inspecting the trained models.
翻译:本文研究了在通常环绕拖网捕捞工具的混乱低能见度环境中自动分类聚集行为。本文比较了三种卷积和注意力深度动作识别网络体系结构,这些网络体系结构在由远程控制摄像机捕捉的一小组视频序列上进行了端到端的训练,并由渔业技术专家进行分类。这些序列描绘了一个拖网前方的场景,其中传统的聚集机制被定向激光光线取代。目标是检测序列中是否存在鱼并分类鱼是否对激光有反应。针对三类任务,通过两个流 CNN 模型、CNN-transformer 混合体和纯 transformer 模型的端到端训练,分别与人类专家相比,实现了 63%、54% 和 60% 的十折分类准确度。检查三个网络学习的激活图引发了关于模型可能学习的序列属性的问题,特别是摄像机操作者引入的视点变化,可能会影响视频帧中激光线的位置,从而干扰分类。这强调了捕捉科学数据进行自动端到端评估时,精心的实验设计的重要性,以及检查训练模型的有用性。