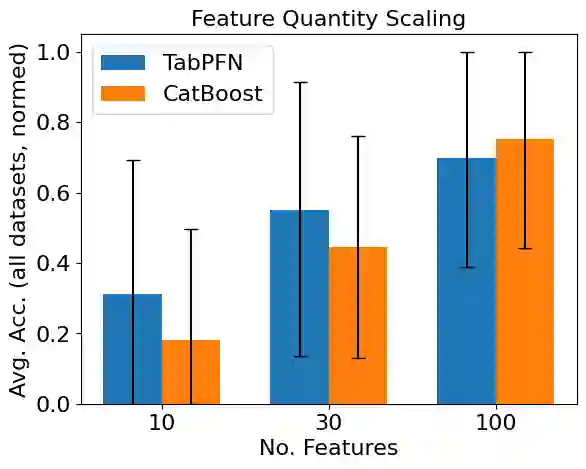
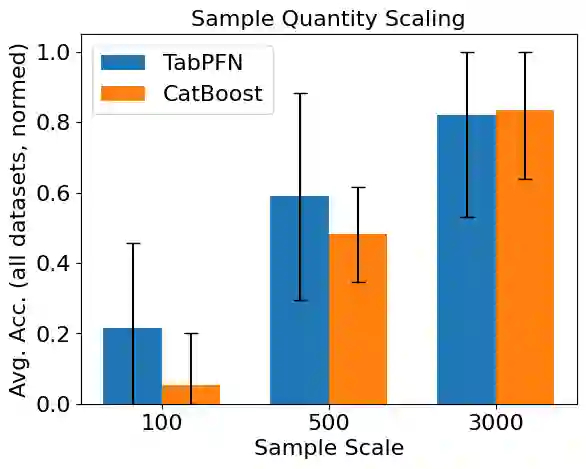
Tabular classification has traditionally relied on supervised algorithms, which estimate the parameters of a prediction model using its training data. Recently, Prior-Data Fitted Networks (PFNs) such as TabPFN have successfully learned to classify tabular data in-context: the model parameters are designed to classify new samples based on labelled training samples given after the model training. While such models show great promise, their applicability to real-world data remains limited due to the computational scale needed. Here we study the following question: given a pre-trained PFN for tabular data, what is the best way to summarize the labelled training samples before feeding them to the model? We conduct an initial investigation of sketching and feature-selection methods for TabPFN, and note certain key differences between it and conventionally fitted tabular models.
翻译:暂无翻译