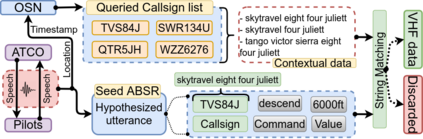
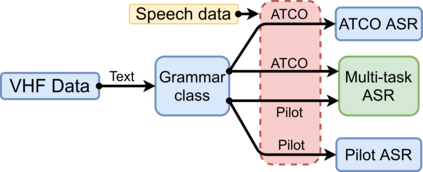
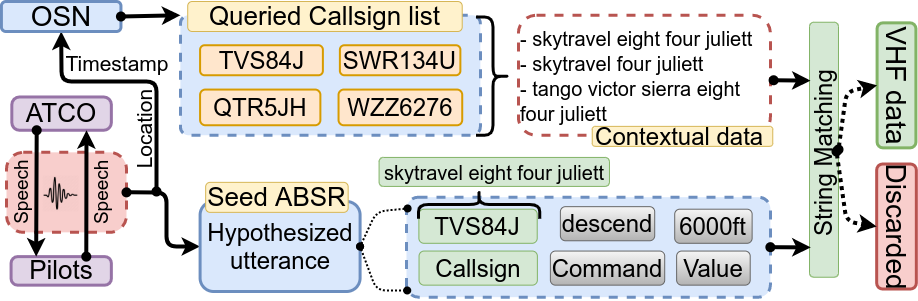
Assistant Based Speech Recognition (ABSR) for air traffic control is generally trained by pooling both Air Traffic Controller (ATCO) and pilot data. In practice, this is motivated by the fact that the proportion of pilot data is lesser compared to ATCO while their standard language of communication is similar. However, due to data imbalance of ATCO and pilot and their varying acoustic conditions, the ASR performance is usually significantly better for ATCOs than pilots. In this paper, we propose to (1) split the ATCO and pilot data using an automatic approach exploiting ASR transcripts, and (2) consider ATCO and pilot ASR as two separate tasks for Acoustic Model (AM) training. For speaker role classification of ATCO and pilot data, a hypothesized ASR transcript is generated with a seed model, subsequently used to classify the speaker role based on the knowledge extracted from grammar defined by International Civil Aviation Organization (ICAO). This approach provides an average speaker role identification accuracy of 83% for ATCO and pilot. Finally, we show that training AMs separately for each task, or using a multitask approach is well suited for this data compared to AM trained by pooling all data.
翻译:空中交通管制助理语音识别系统(ABSR)一般通过将空中交通管制管理员(ATCO)和试验数据汇集在一起来培训空中交通管制方面的助理语音识别系统(ABSR),实际上,这是由于试验数据的比例比ATCO少,而其标准通信语言类似,但是由于ATCO的数据不平衡和试验以及不同的声学条件,ASR的性能通常比试验者要好得多。在本文中,我们提议(1)利用ASR记录誊本自动将ATCO和试验数据分开使用自动方法,(2)将ATCO和试验ASR视为两个单独的训练任务。关于ATCO和试验数据的演讲人角色分类和试验数据,用种子模型生成了一个虚小的ASR记录,随后用来根据从国际民用航空组织(民航组织)的语法界定的知识对演讲人的角色进行分类。这种方法为ATCO和试验提供了平均83%的演讲人角色识别精确度。最后,我们表明,对每项任务分别进行培训,或采用多任务方式,与通过汇集所有数据来训练的AM相比,我们非常适合这一数据。