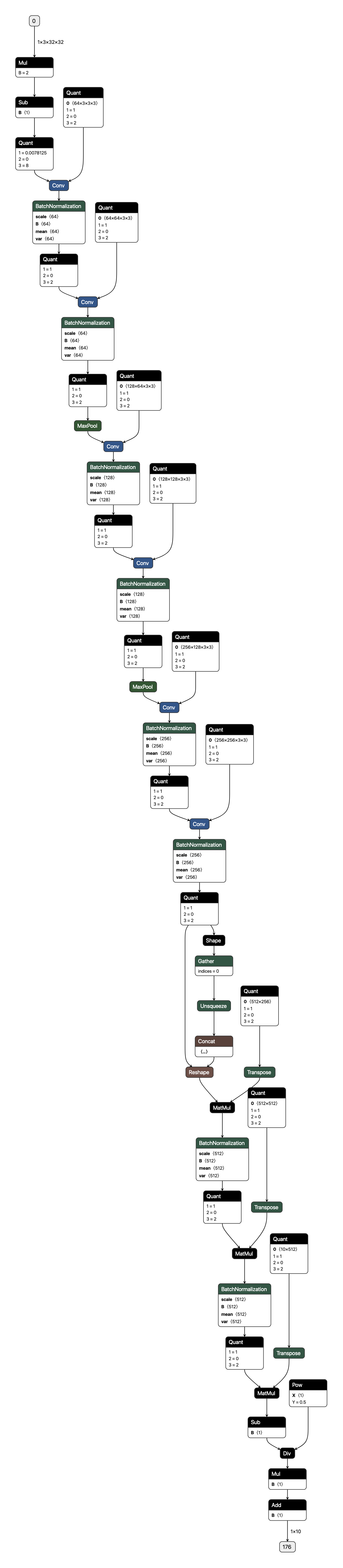
We present extensions to the Open Neural Network Exchange (ONNX) intermediate representation format to represent arbitrary-precision quantized neural networks. We first introduce support for low precision quantization in existing ONNX-based quantization formats by leveraging integer clipping, resulting in two new backward-compatible variants: the quantized operator format with clipping and quantize-clip-dequantize (QCDQ) format. We then introduce a novel higher-level ONNX format called quantized ONNX (QONNX) that introduces three new operators -- Quant, BipolarQuant, and Trunc -- in order to represent uniform quantization. By keeping the QONNX IR high-level and flexible, we enable targeting a wider variety of platforms. We also present utilities for working with QONNX, as well as examples of its usage in the FINN and hls4ml toolchains. Finally, we introduce the QONNX model zoo to share low-precision quantized neural networks.
翻译:我们推出开放神经网络交换(ONNX)中间代表格式的扩展,以代表任意精度分解神经网络。我们首先通过利用整分剪切,在现有的基于ONNX的量化格式中引入对低精度量化的支持,结果产生了两个新的后向兼容变体:带有剪切和分分分剪分分分分分分分分数(QCDQQQ)格式的量化操作器格式。然后我们引入了新型的更高级的ONX格式,称为量化的ONNX(QONNX)格式,其中引入了三个新的操作器 -- -- Quant、双极Quant和Trunc -- -- 以代表统一的量化。通过保持QONNX IR高水平和灵活,我们能够针对更广泛的平台。我们还介绍了与QONNX合作(QCDQ)合作的公用事业,以及它在FINN和hls4mol工具链中的使用实例。最后,我们引入了QONX模型动物园,以分享低精度分剖腹神经网络。