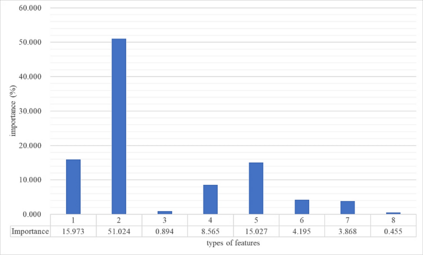
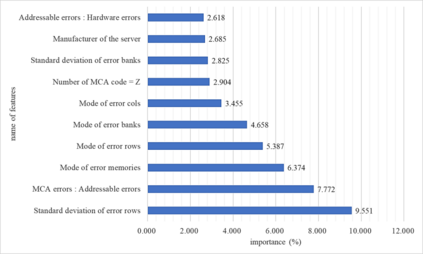
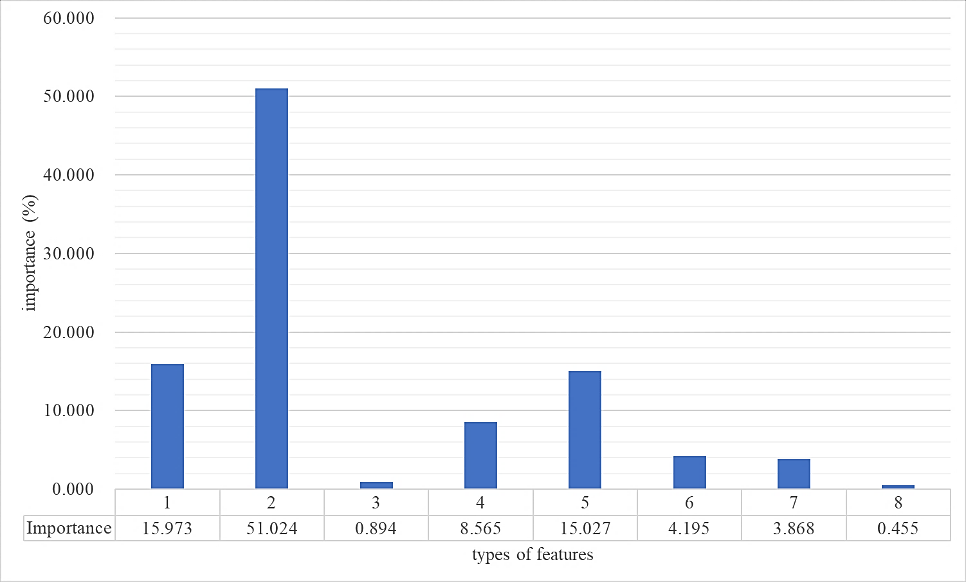
In the data center, unexpected downtime caused by memory failures can lead to a decline in the stability of the server and even the entire information technology infrastructure, which harms the business. Therefore, whether the memory failure can be accurately predicted in advance has become one of the most important issues to be studied in the data center. However, for the memory failure prediction in the production system, it is necessary to solve technical problems such as huge data noise and extreme imbalance between positive and negative samples, and at the same time ensure the long-term stability of the algorithm. This paper compares and summarizes some commonly used skills and the improvement they can bring. The single model we proposed won the top 14th in the 2nd Alibaba Cloud AIOps Competition belonging to the 25th PAKDD conference. It takes only 30 minutes to pass the online test, while most of the other contestants' solution need more than 3 hours. Codes has been open source to https://www.github.com/ycd2016/acaioc2.
翻译:在数据中心,由于记忆失灵造成的意外停机,可能导致服务器的稳定性下降,甚至整个信息技术基础设施的稳定性下降,从而对企业造成损害。因此,能否准确提前预测记忆失灵已成为数据中心研究的最重要问题之一。然而,对于生产系统中的记忆失灵预测,必须解决技术问题,如数据噪音巨大,正式和负式样本之间的极端不平衡,同时确保算法的长期稳定性。本文比较并概述了一些常用的技能以及它们能够带来的改进。我们提出的单一模型赢得了属于第二十五届泛太平洋数字系统会议的第二届阿里巴巴云类国际电算项目竞赛的第十四届第一位。通过在线测试只需要30分钟,而其他参赛者大多需要超过3小时的解决方案。代码已经向https://www.github.com/ycd2016/acaioc2开放。