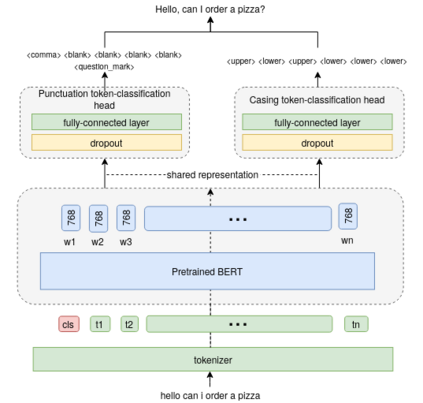
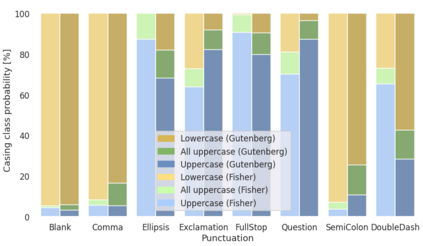
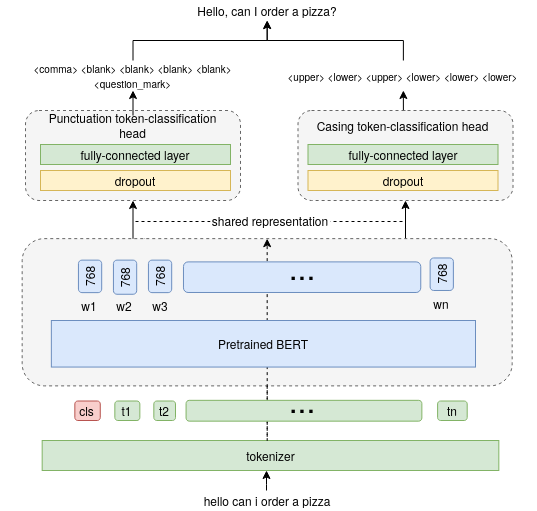
Capitalization and punctuation are important cues for comprehending written texts and conversational transcripts. Yet, many ASR systems do not produce punctuated and case-formatted speech transcripts. We propose to use a multi-task system that can exploit the relations between casing and punctuation to improve their prediction performance. Whereas text data for predicting punctuation and truecasing is seemingly abundant, we argue that written text resources are inadequate as training data for conversational models. We quantify the mismatch between written and conversational text domains by comparing the joint distributions of punctuation and word cases, and by testing our model cross-domain. Further, we show that by training the model in the written text domain and then transfer learning to conversations, we can achieve reasonable performance with less data.
翻译:资本化和标点是理解书面文本和谈话记录的重要线索。然而,许多ASR系统并不产生标点和以案件格式格式的语音记录。我们提议使用一个多任务系统,利用弹壳和标点之间的关系来改善它们的预测性能。虽然预测标点和真伪的文本数据似乎很丰富,但我们认为,书面文本资源作为对话模型的培训数据是不够的。我们通过比较标点和字词案例的联合分布,并通过测试我们的跨域模型来量化书面文本和谈话文本之间的不匹配。此外,我们表明,通过在书面文本领域培训模型,然后将学习转移到对话领域,我们可以以较少的数据实现合理的业绩。