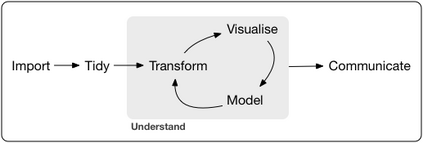
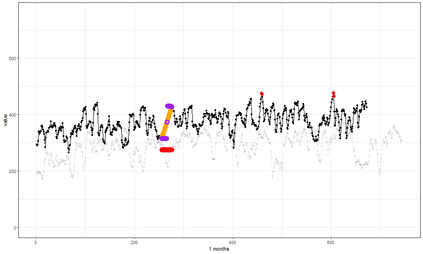
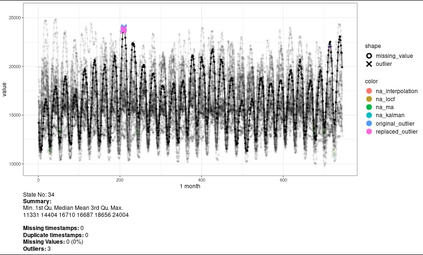
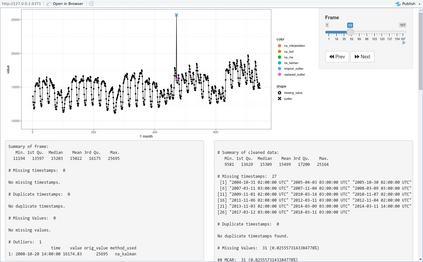
Data cleaning is one of the most important tasks in data analysis processes. One of the perennial challenges in data analytics is the detection and handling of non-valid data. Failing to do so can result in inaccurate analytics and unreliable decisions. The process of properly cleaning such data takes much time. Errors are prevalent in time series data. It is usually found that real world data is unclean and requires some pre-processing. The analysis of large amounts of data is difficult. This paper is intended to provide an easy to use and reliable system which automates the cleaning process of univariate time series data. Automating the process greatly reduces the time required. Visualizing a large amount of data at once is not very effective. To tackle this issue, an R package cleanTS is proposed. The proposed system provides a way to analyze data on different scales and resolutions. Also, it provides users with tools and a benchmark system for comparing various techniques used in data cleaning.
翻译:数据清理是数据分析过程中最重要的任务之一。数据分析过程中的常年挑战之一是检测和处理非有效数据。不这样做可能导致分析不准确和不可靠的决定。适当清理这些数据的过程需要很长的时间。错误在时间序列数据中很普遍。通常发现真实世界数据不干净,需要一些预处理。分析大量数据很困难。本文件旨在提供一个易于使用和可靠的系统,使单流时间序列数据的清理过程自动化。自动化过程大大缩短了所需时间。对大量数据的视觉化并不十分有效。为了解决这一问题,建议采用R包清洁技术。拟议的系统为分析不同尺度和分辨率的数据提供了一种方法。此外,该系统还为用户提供了工具,并提供了一个基准系统,用于比较数据清理中所使用的各种技术。