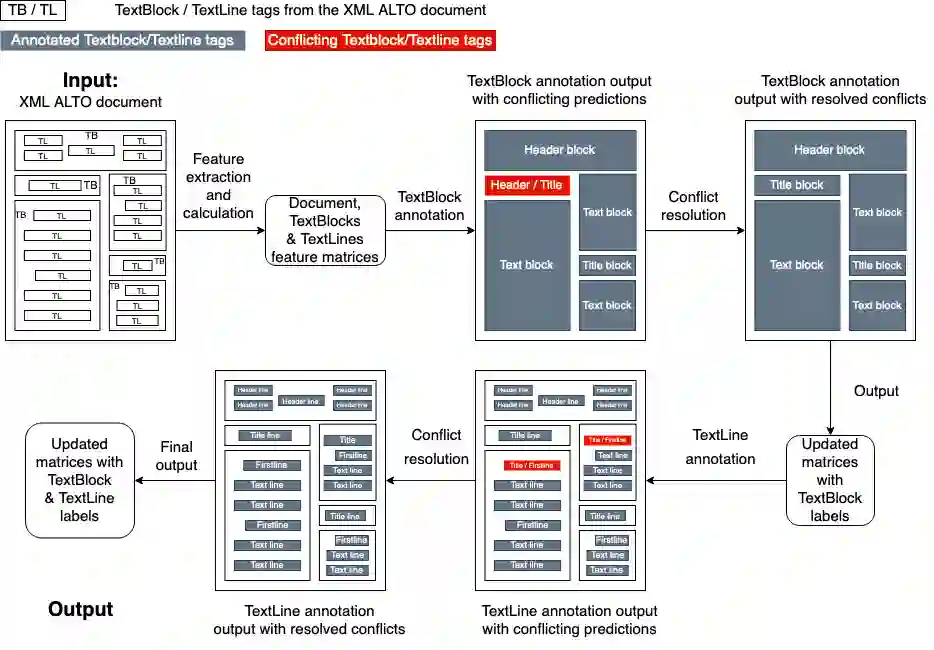
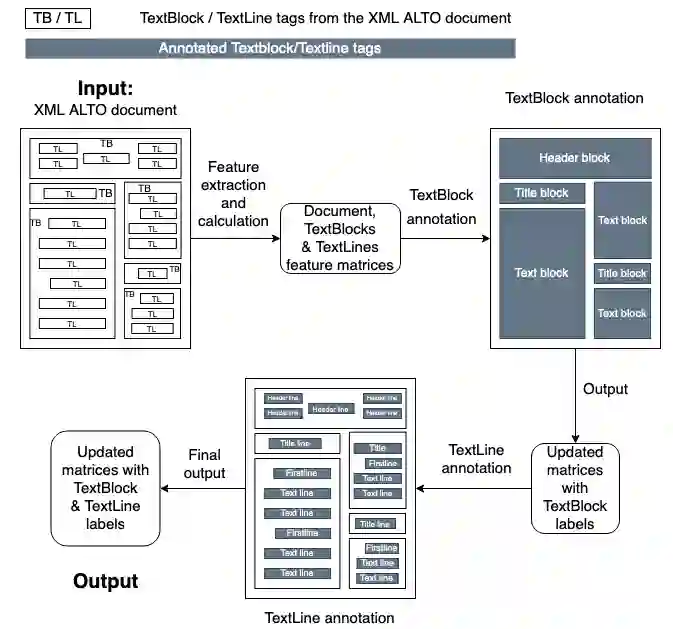
Background. In recent years, libraries and archives led important digitisation campaigns that opened the access to vast collections of historical documents. While such documents are often available as XML ALTO documents, they lack information about their logical structure. In this paper, we address the problem of Logical Layout Analysis applied to historical documents in French. We propose a rule-based method, that we evaluate and compare with two Machine-Learning models, namely RIPPER and Gradient Boosting. Our data set contains French newspapers, periodicals and magazines, published in the first half of the twentieth century in the Franche-Comt\'e Region. Results. Our rule-based system outperforms the two other models in nearly all evaluations. It has especially better Recall results, indicating that our system covers more types of every logical label than the other two models. When comparing RIPPER with Gradient Boosting, we can observe that Gradient Boosting has better Precision scores but RIPPER has better Recall scores. Conclusions. The evaluation shows that our system outperforms the two Machine Learning models, and provides significantly higher Recall. It also confirms that our system can be used to produce annotated data sets that are large enough to envisage Machine Learning or Deep Learning approaches for the task of Logical Layout Analysis. Combining rules and Machine Learning models into hybrid systems could potentially provide even better performances. Furthermore, as the layout in historical documents evolves rapidly, one possible solution to overcome this problem would be to apply Rule Learning algorithms to bootstrap rule sets adapted to different publication periods.
翻译:近几年来, 图书馆和档案导致重要的数字化运动, 开放了大量历史文件收藏。 虽然这类文件通常以 XML ALTO 文件的形式提供, 但缺乏关于逻辑结构的信息。 在本文中, 我们处理历史文件应用到法文的逻辑布局分析问题。 我们建议一种基于规则的方法, 我们用两种机器学习模式, 即 RIPPER 和 Gradient Bushing 来评估和比较。 我们的数据集包含20世纪上半叶在Franche-Comt\'e区域出版的法国报纸、 期刊和杂志。 结果。 我们的基于规则的系统在几乎所有的评价中都超越了另外两种模式。 它特别更好地回顾结果, 表明我们的系统比其他两种模式都包含更多的逻辑标签。 当我们比较 RIPPER 和 Gradient Bushing 模型时, 我们可以看到, 梯级布局的分数比预估分要好, 但是RIPPER 会比分数要好。 评估表明, 我们的系统比两个机器学习模型要差得多, 并且提供更高级的更高级的 更深层次的 规则 。 它还确认我们使用了我们的系统, 的系统, 学习的流程的流程的流程, 的流程是用来去变的系统,, 做一个更可能的系统, 做一个更精确的系统, 的流程的流程, 做为历史的系统, 的流程的流程的流程的流程的流程的流程的变的变。