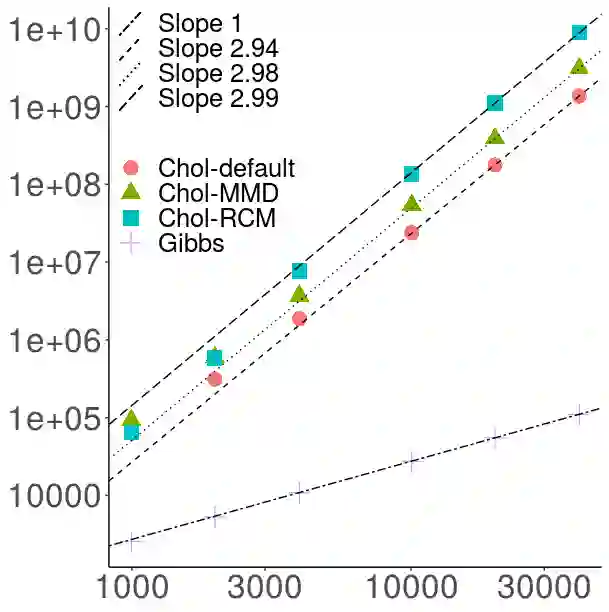
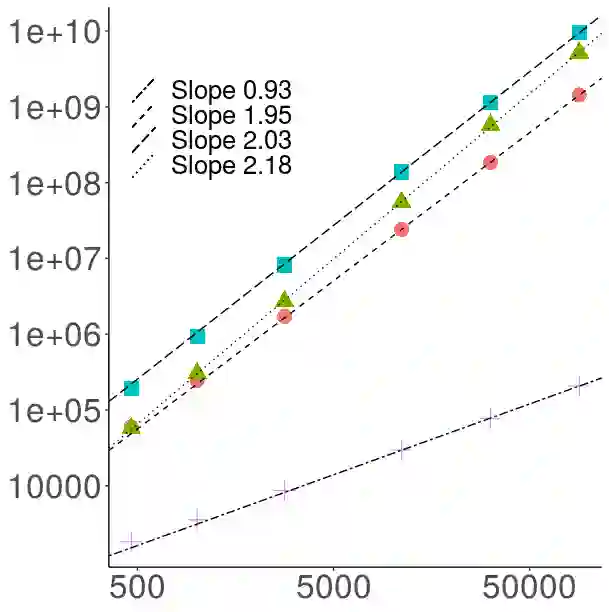
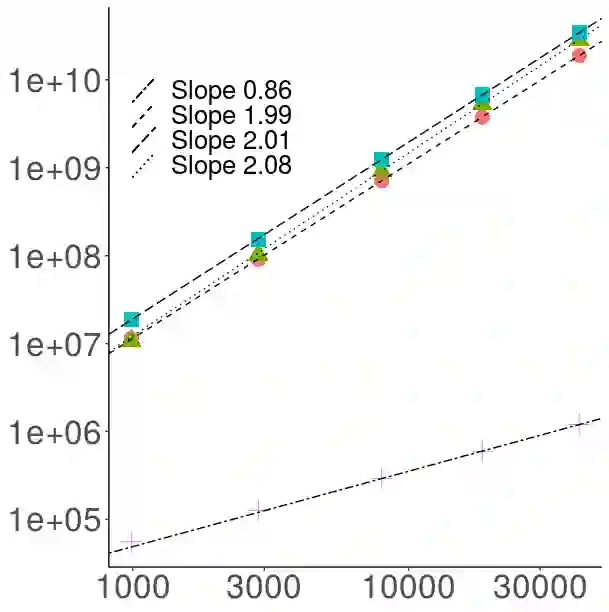
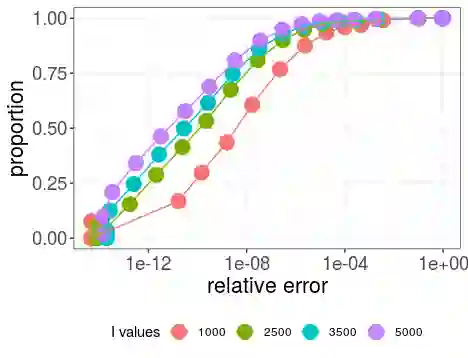
The article is about algorithms for learning Bayesian hierarchical models, the computational complexity of which scales linearly with the number of observations and the number of parameters in the model. It focuses on crossed random effect and nested multilevel models, which are used ubiquitously in applied sciences, and illustrates the methodology on two challenging real data analyses on predicting electoral results and real estate prices respectively. The posterior dependence in both classes is sparse: in crossed random effects models it resembles a random graph, whereas in nested multilevel models it is tree-structured. For each class we develop a framework for scalable computation based on collapsed Gibbs sampling and belief propagation respectively. We provide a number of negative (for crossed) and positive (for nested) results for the scalability (or lack thereof) of methods based on sparse linear algebra, which are relevant also to Laplace approximation methods for such models. Our numerical experiments compare with off-the-shelf variational approximations and Hamiltonian Monte Carlo. Our theoretical results, although partial, are useful in suggesting interesting methodologies and lead to conclusions that our numerics suggest to hold well beyond the scope of the underlying assumptions.
翻译:文章是关于学习巴伊西亚等级模型的算法, 其计算复杂性以观察次数和模型参数数为线性尺度, 侧重于超随机效应和嵌套多级模型, 应用科学中均使用这些模型, 并展示了两种具有挑战性的实际数据分析方法, 分别用于预测选举结果和房地产价格。 两类的后继依赖性都很少: 在跨随机效应模型中, 它类似于随机图, 在嵌套多级模型中, 它是树形结构的。 对于每一类, 我们分别根据崩溃的Gibbs抽样和信仰传播制定可缩放计算框架。 我们提供了一些负面( 跨) 和正( 嵌套) 的结果, 以稀薄线性代数为基础的方法的可缩放性( 或缺乏) 方法, 也与这些模型的拉普特近比法有关。 我们的数值实验与现成的变差近近和汉密尔顿· 蒙特卡洛比较。 我们的理论结果虽然部分, 有助于提出有趣的方法, 并导致结论, 我们的数值显示我们的数字显示我们的数值远远超出基本假设的范围。