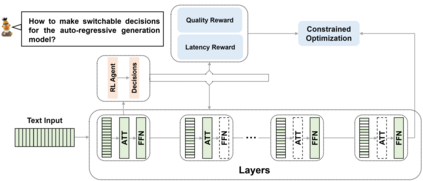
Auto-regressive generation models achieve competitive performance across many different NLP tasks such as summarization, question answering, and classifications. However, they are also known for being slow in inference, which makes them challenging to deploy in real-time applications. We propose a switchable decision to accelerate inference by dynamically assigning computation resources for each data instance. Automatically making decisions on where to skip and how to balance quality and computation cost with constrained optimization, our dynamic neural generation networks enforce the efficient inference path and determine the optimized trade-off. Experiments across question answering, summarization, and classification benchmarks show that our method benefits from less computation cost during inference while keeping the same accuracy. Extensive experiments and ablation studies demonstrate that our method can be general, effective, and beneficial for many NLP tasks.
翻译:暂无翻译