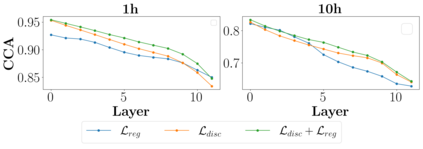
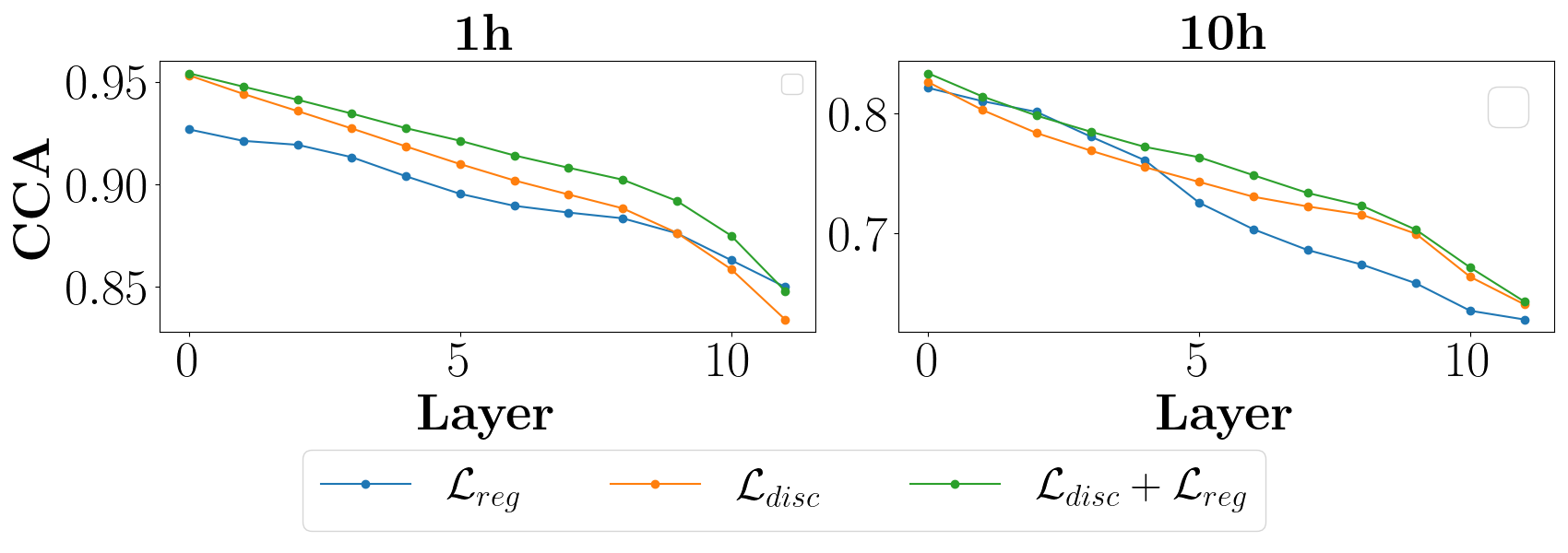
Recent years have witnessed great strides in self-supervised learning (SSL) on the speech processing. The SSL model is normally pre-trained on a great variety of unlabelled data and a large model size is preferred to increase the modeling capacity. However, this might limit its potential applications due to the expensive computation and memory costs introduced by the oversize model. Miniaturization for SSL models has become an important research direction of practical value. To this end, we explore the effective distillation of HuBERT-based SSL models for automatic speech recognition (ASR). First, in order to establish a strong baseline, a comprehensive study on different student model structures is conducted. On top of this, as a supplement to the regression loss widely adopted in previous works, a discriminative loss is introduced for HuBERT to enhance the distillation performance, especially in low-resource scenarios. In addition, we design a simple and effective algorithm to distill the front-end input from waveform to Fbank feature, resulting in 17% parameter reduction and doubling inference speed, at marginal performance degradation.
翻译:近年来,在语言处理方面的自我监督学习(SSL)取得了长足的进步。 SSL模型通常在大量无标签数据上经过预先培训,而且为了提高模型的建模能力,更倾向于使用大型号模型,但这可能会限制其潜在的应用,因为超规模模型的计算和记忆成本昂贵。 SSL模型的微型化已成为一项具有实际价值的重要研究方向。 为此,我们探索了基于HuBERT的SLS模型的有效蒸馏,以便自动语音识别。 首先,为了建立强有力的基线,对不同的学生模型结构进行了全面研究。除此之外,作为对以往工作中广泛采用的回归损失的补充,对HuBERT提出了歧视性损失,以提高蒸馏性能,特别是在低资源情景中。此外,我们设计了简单有效的算法,以提炼从波形到Fbank特性的前端输入,导致17 %的参数降低和加倍的推导速度,在边际性能退化时。