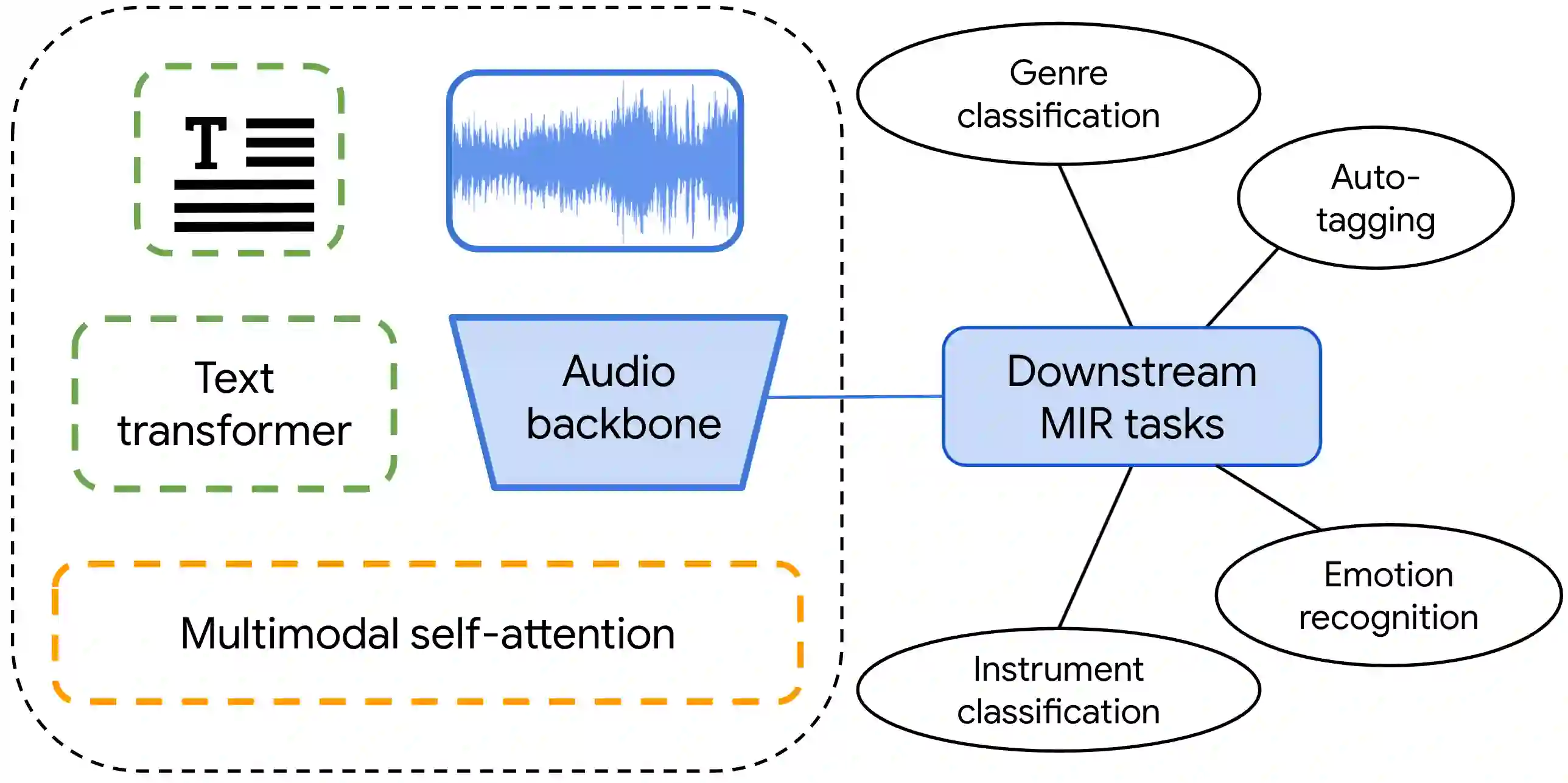
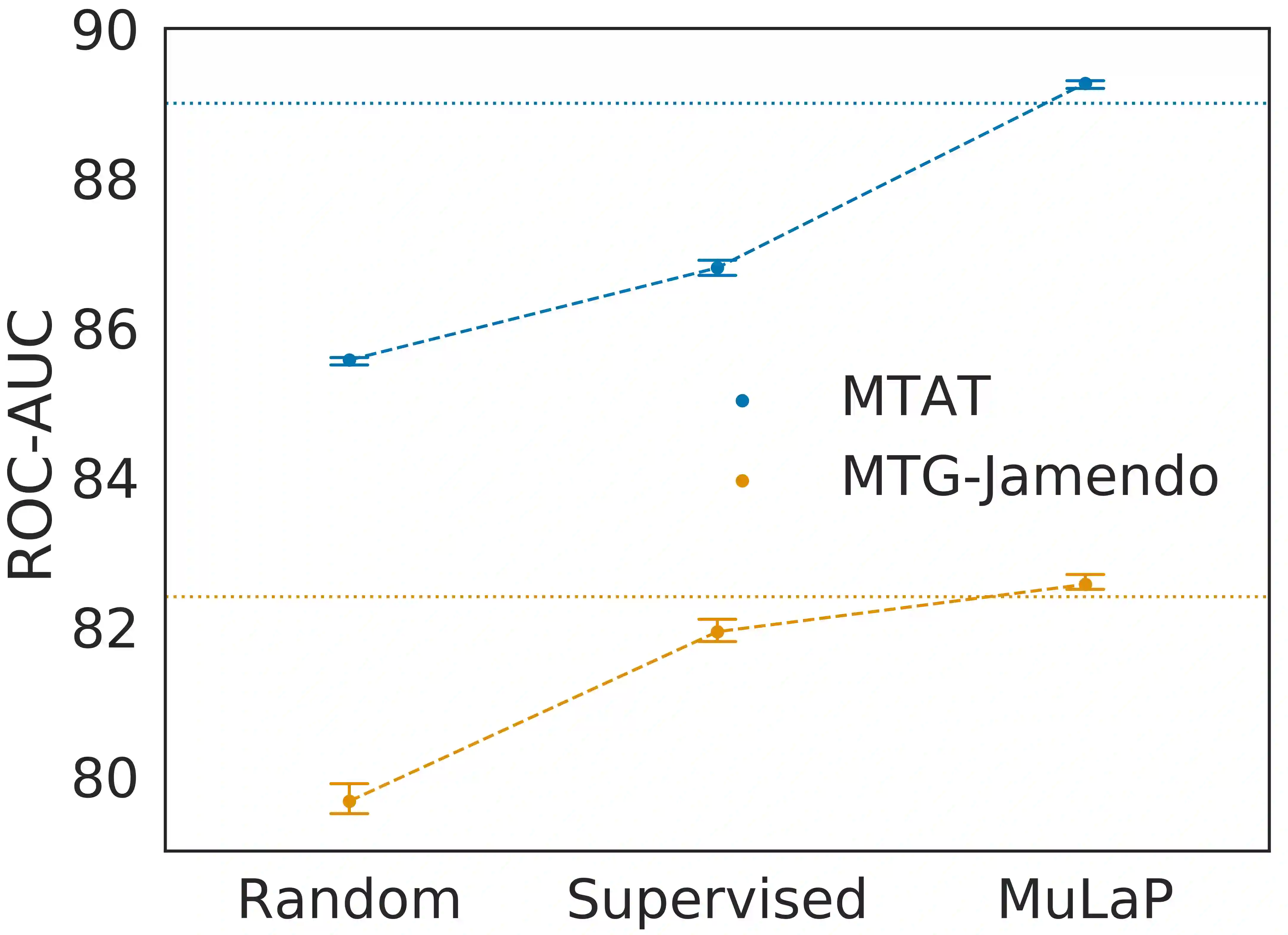
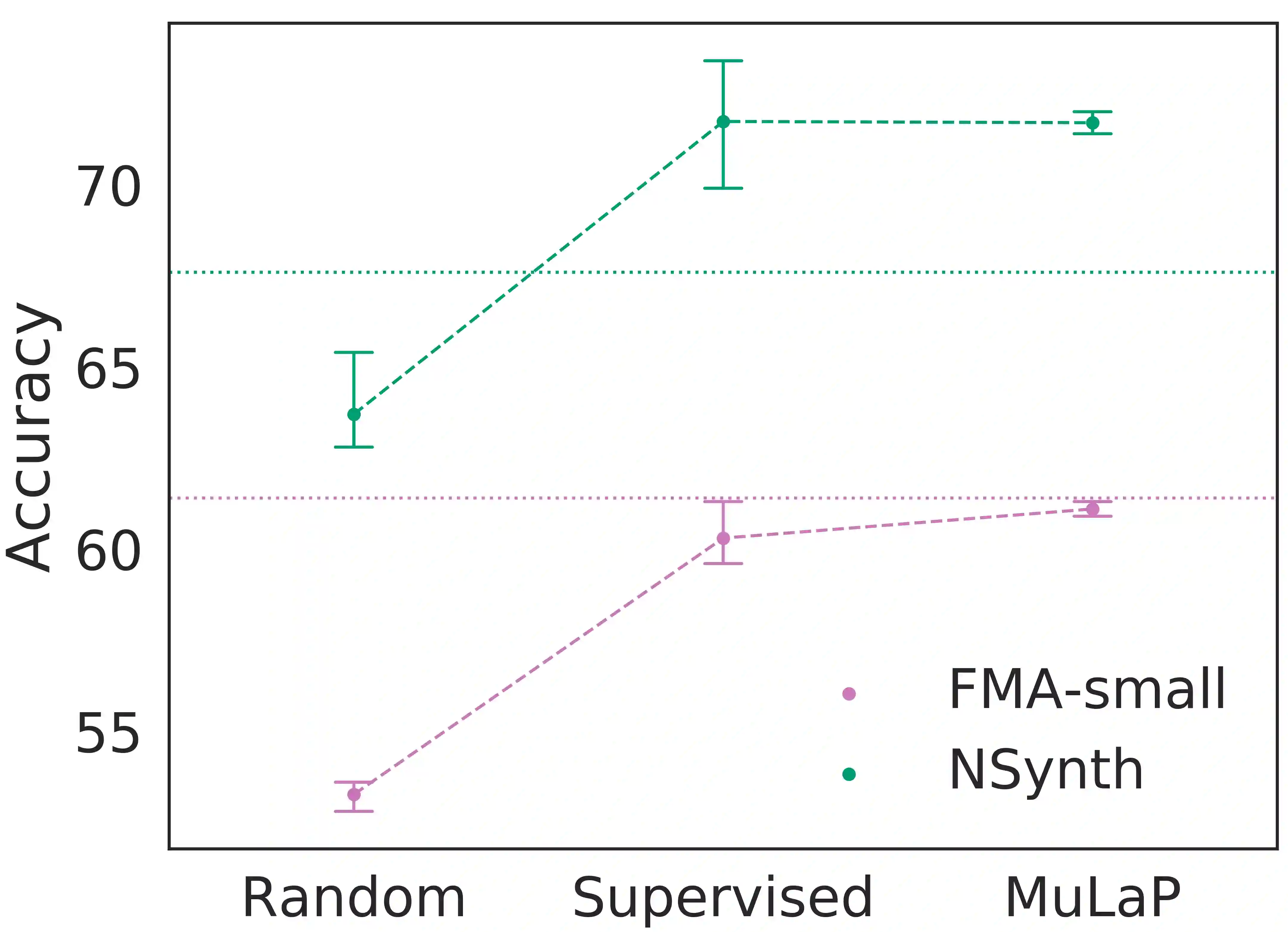
Audio representations for music information retrieval are typically learned via supervised learning in a task-specific fashion. Although effective at producing state-of-the-art results, this scheme lacks flexibility with respect to the range of applications a model can have and requires extensively annotated datasets. In this work, we pose the question of whether it may be possible to exploit weakly aligned text as the only supervisory signal to learn general-purpose music audio representations. To address this question, we design a multimodal architecture for music and language pre-training (MuLaP) optimised via a set of proxy tasks. Weak supervision is provided in the form of noisy natural language descriptions conveying the overall musical content of the track. After pre-training, we transfer the audio backbone of the model to a set of music audio classification and regression tasks. We demonstrate the usefulness of our approach by comparing the performance of audio representations produced by the same audio backbone with different training strategies and show that our pre-training method consistently achieves comparable or higher scores on all tasks and datasets considered. Our experiments also confirm that MuLaP effectively leverages audio-caption pairs to learn representations that are competitive with audio-only and cross-modal self-supervised methods in the literature.
翻译:在这项工作中,我们提出了一个问题,即是否有可能利用不一致的文字作为学习一般用途音乐音频演示的唯一监督信号。为了解决这一问题,我们设计了一个通过一套代理任务优化的音乐和语言预培训(MuLaP)的多式联运结构。虽然这种制度在产生最新成果方面是有效的,但在模型可以具有和需要大量附加说明的数据集的应用范围方面缺乏灵活性。在这项工作中,我们提出了一个问题,即是否有可能利用不一致的文字作为学习一般用途音乐音频演示的唯一监督信号。为了解决这一问题,我们设计了一个通过一套代理任务优化的音乐和语言预培训(MuLaP)的多式联运结构。微弱的监管是以传达轨道整体音乐内容的噪音自然语言描述形式提供的。在培训前,我们将模型的音力支柱转移到一套音乐音频分类和回归任务。我们通过将同一音频主干制作的音频演示的性能与不同的培训战略进行比较,表明我们的预培训方法在所考虑的所有任务和数据集上都始终达到可比或更高的分数。我们的实验还证实,MulaP有效地利用音带对具有竞争力的手法和跨式的文学演示。