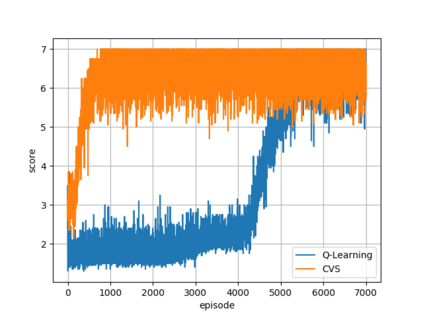
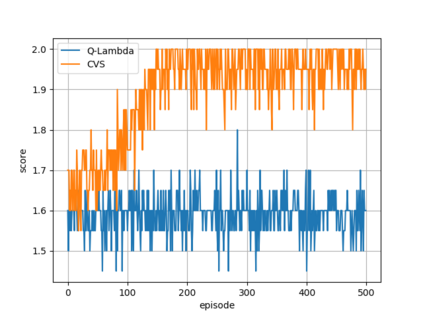
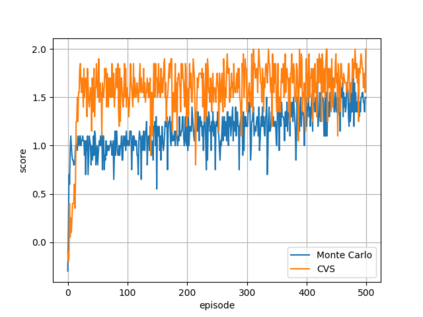
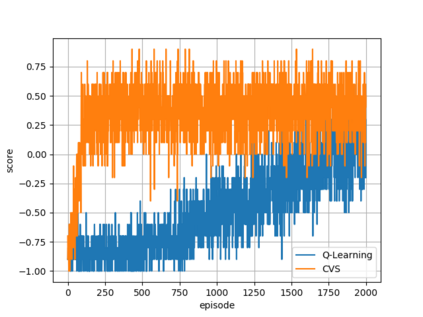
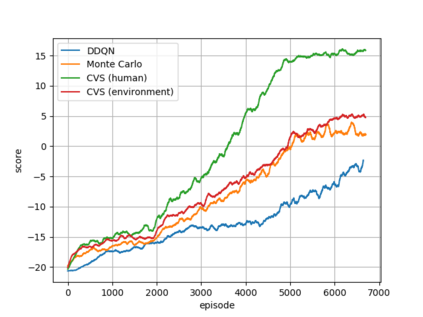
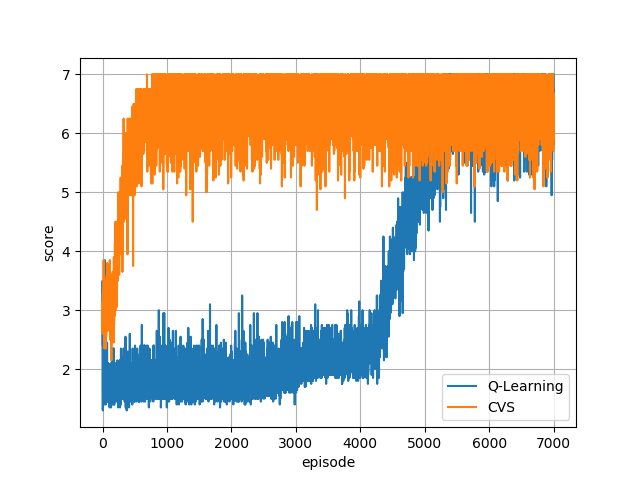
In the context of reinforcement learning we introduce the concept of criticality of a state, which indicates the extent to which the choice of action in that particular state influences the expected return. That is, a state in which the choice of action is more likely to influence the final outcome is considered as more critical than a state in which it is less likely to influence the final outcome. We formulate a criticality-based varying step number algorithm (CVS) - a flexible step number algorithm that utilizes the criticality function provided by a human, or learned directly from the environment. We test it in three different domains including the Atari Pong environment, Road-Tree environment, and Shooter environment. We demonstrate that CVS is able to outperform popular learning algorithms such as Deep Q-Learning and Monte Carlo.
翻译:在强化学习方面,我们引入了国家关键度概念,这说明特定国家的行动选择对预期回报的影响程度。也就是说,选择行动更有可能影响最终结果的状态被认为比它不太可能影响最终结果的状态更为关键。我们制定了基于临界度的不同级数算法(CVS) — — 一种灵活级数算法,利用人类提供的关键度功能,或直接从环境中学习。我们用三个不同领域进行测试,包括阿塔里蓬环境、路轨环境和射击环境。我们证明,CVS能够超越深Q-学习和蒙特卡洛等大众学习算法。