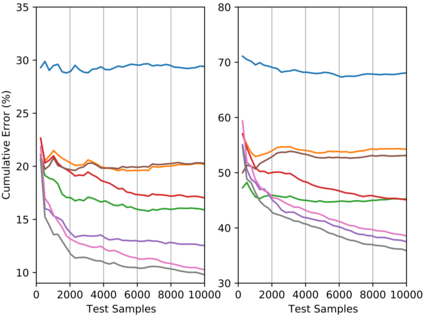
Deploying models on target domain data subject to distribution shift requires adaptation. Test-time training (TTT) emerges as a solution to this adaptation under a realistic scenario where access to full source domain data is not available and instant inference on target domain is required. Despite many efforts into TTT, there is a confusion over the experimental settings, thus leading to unfair comparisons. In this work, we first revisit TTT assumptions and categorize TTT protocols by two key factors. Among the multiple protocols, we adopt a realistic sequential test-time training (sTTT) protocol, under which we further develop a test-time anchored clustering (TTAC) approach to enable stronger test-time feature learning. TTAC discovers clusters in both source and target domain and match the target clusters to the source ones to improve generalization. Pseudo label filtering and iterative updating are developed to improve the effectiveness and efficiency of anchored clustering. We demonstrate that under all TTT protocols TTAC consistently outperforms the state-of-the-art methods on five TTT datasets. We hope this work will provide a fair benchmarking of TTT methods and future research should be compared within respective protocols. A demo code is available at https://github.com/Gorilla-Lab-SCUT/TTAC.
翻译:测试时间培训(TTTT)是在现实的情景下出现的,在现实的情景下,无法获取全部源域数据,需要立即对目标域作出推断。尽管在TTT中作出了许多努力,但实验环境混乱,从而导致不公平的比较。在这项工作中,我们首先重新审查TTTT假设,按两个关键因素对TTT协议进行分类。在多个协议中,我们采用现实的连续测试时间培训协议,根据该协议,我们进一步制定测试时间定位集群(TTAC)方法,以便能够加强测试时间特性学习。TTAC发现源域和目标域的集群,并将目标集群与源域挂钩,以改进一般化。正在开发Pseudo标签过滤和迭代更新,以提高锁定集群的效力和效率。我们证明,在所有TTAC协议下,TTAC始终在五个TTT数据集上超越了状态-艺术方法。我们希望这项工作将为TTTT方法提供公平的基准化方法,未来研究将在各自的协议中进行测试。ATTT/GUBA/TUD的代码中可以比较。