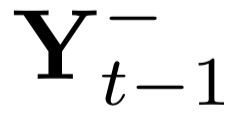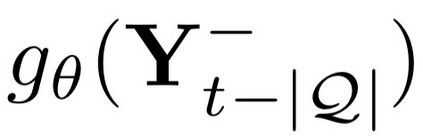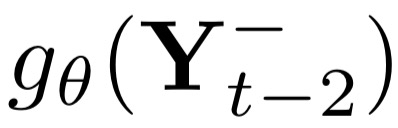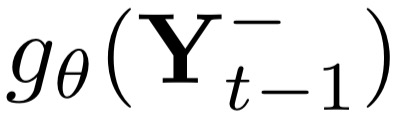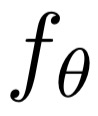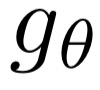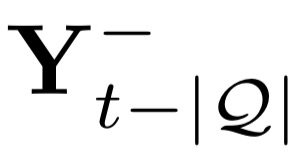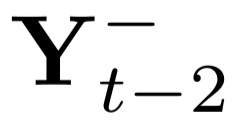Deep candidate generation (DCG) that narrows down the collection of relevant items from billions to hundreds via representation learning is essential to large-scale recommender systems. Standard approaches approximate maximum likelihood estimation (MLE) through sampling for better scalability and address the problem of DCG in a way similar to language modeling. However, live recommender systems face severe unfairness of exposure with a vocabulary several orders of magnitude larger than that of natural language, implying that (1) MLE will preserve and even exacerbate the exposure bias in the long run in order to faithfully fit the observed samples, and (2) suboptimal sampling and inadequate use of item features can lead to inferior representations for the unfairly ignored items. In this paper, we introduce CLRec, a Contrastive Learning paradigm that has been successfully deployed in a real-world massive recommender system, to alleviate exposure bias in DCG. We theoretically prove that a popular choice of contrastive loss is equivalently reducing the exposure bias via inverse propensity scoring, which provides a new perspective on the effectiveness of contrastive learning. We further employ a fixed-size queue to store the items' representations computed in previously processed batches, and use the queue to serve as an effective sampler of negative examples. This queue-based design provides great efficiency in incorporating rich features of the thousand negative items per batch thanks to computation reuse. Extensive offline analyses and four-month online A/B tests in Mobile Taobao demonstrate substantial improvement, including a dramatic reduction in the Matthew effect.
翻译:通过代表制学习将相关物品的收集从数十亿减少到数百个的深度候选人一代(DCG),通过代表制学习将相关物品的收集从数十亿缩小到数百个,这对于大规模推荐制度至关重要。标准做法通过抽样估计,可能达到最大可能性估计(MLE),以便更便于缩放,并以类似于语言模型的方式解决DCG的问题。然而,现场推荐者系统面临严重不公平的暴露,使用比自然语言大得多的词汇数量级,意味着(1) MLE将保持甚至加剧长期的暴露偏差,以便忠实地适应所观察到的样本;(2) 物品特征的不优化取样和不当使用可能导致不公平被忽视物品的描述出现劣势。 在本文件中,我们引入了CLRec,即一种对比性学习模式,在现实世界大规模推荐系统中成功部署,以缓解DCG的暴露偏差。 我们理论上证明,大众选择对比性损失等于通过反偏差的偏差分评分来减少接触偏差,这为对比性学习的实效提供了新的视角。我们进一步采用固定的排队排档,将产品展示在先前加工过的升级的系列/连续式中进行,包括大幅递减式的递增式的递增式计算。