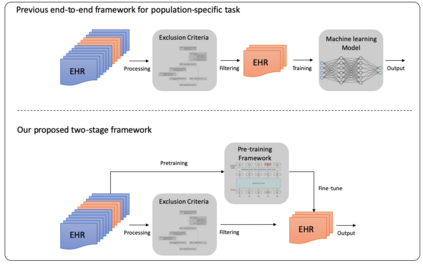
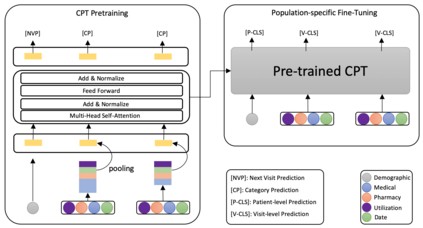
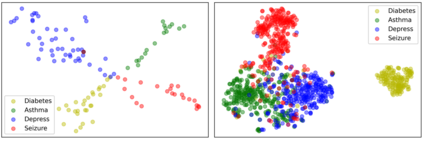
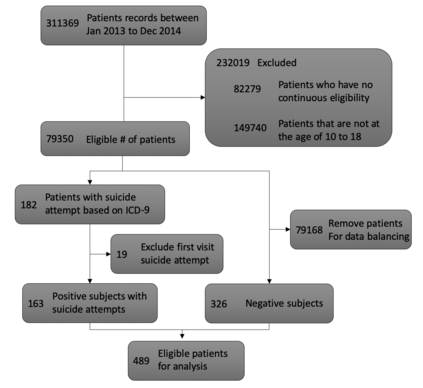
The adoption of electronic health records (EHR) has become universal during the past decade, which has afforded in-depth data-based research. By learning from the large amount of healthcare data, various data-driven models have been built to predict future events for different medical tasks, such as auto diagnosis and heart-attack prediction. Although EHR is abundant, the population that satisfies specific criteria for learning population-specific tasks is scarce, making it challenging to train data-hungry deep learning models. This study presents the Claim Pre-Training (Claim-PT) framework, a generic pre-training model that first trains on the entire pediatric claims dataset, followed by a discriminative fine-tuning on each population-specific task. The semantic meaning of medical events can be captured in the pre-training stage, and the effective knowledge transfer is completed through the task-aware fine-tuning stage. The fine-tuning process requires minimal parameter modification without changing the model architecture, which mitigates the data scarcity issue and helps train the deep learning model adequately on small patient cohorts. We conducted experiments on a real-world claims dataset with more than one million patient records. Experimental results on two downstream tasks demonstrated the effectiveness of our method: our general task-agnostic pre-training framework outperformed tailored task-specific models, achieving more than 10\% higher in model performance as compared to baselines. In addition, our framework showed a great generalizability potential to transfer learned knowledge from one institution to another, paving the way for future healthcare model pre-training across institutions.
翻译:在过去十年中,普遍采用电子健康记录(EHR)的做法在过去十年中成为普遍做法,它提供了深入的基于数据的研究。通过从大量保健数据中学习,建立了各种数据驱动模型,以预测今后各种医疗任务的事件,例如自动诊断和心脏攻击预测。虽然EHR是丰富的,但满足特定人口任务学习具体标准的人口却很少,因此培训数据饥饿深度学习模式具有挑战性。本研究报告介绍了索赔前培训框架,这是一种通用培训前模式,它首先培训整个儿科索赔数据集,然后对每项特定人口任务进行有区别的微调。医学事件的语义含义可以在培训前阶段得到体现,而有效的知识转移是通过任务认知前的微调阶段完成的。微调过程需要在不改变模型结构的情况下进行最低限度的参数修改,这样可以减轻数据短缺问题,并有助于充分培训关于小病人群的深层次学习模式。我们进行了关于真实世界索赔数据集的实验,随后对每项具体人口任务进行了有超过100万份的住院记录进行有区别的微微微微微微微微微微微微调。实验结果显示了我们10个总体培训任务前阶段任务中的一项具体任务。