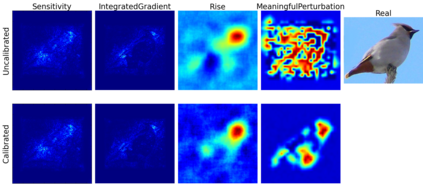
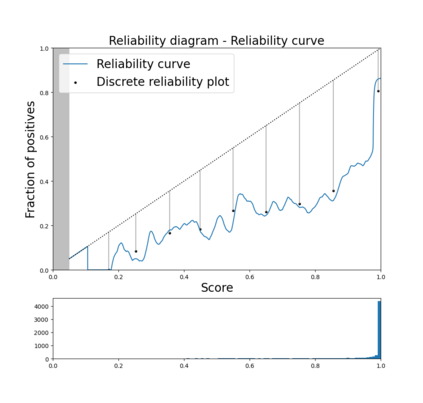
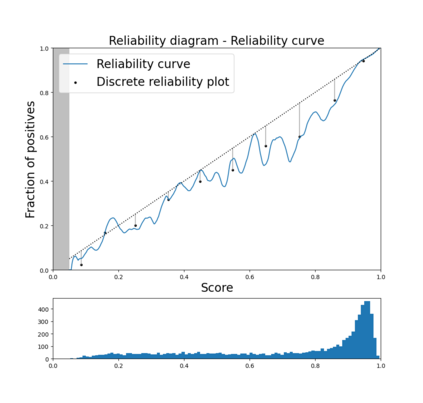
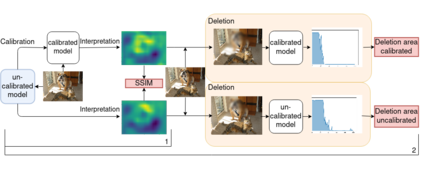
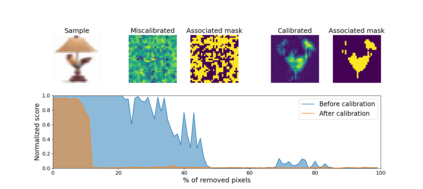
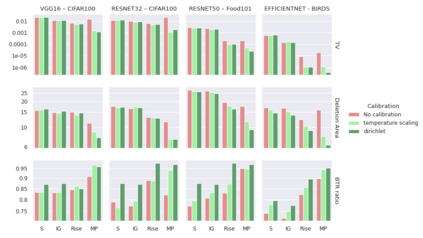
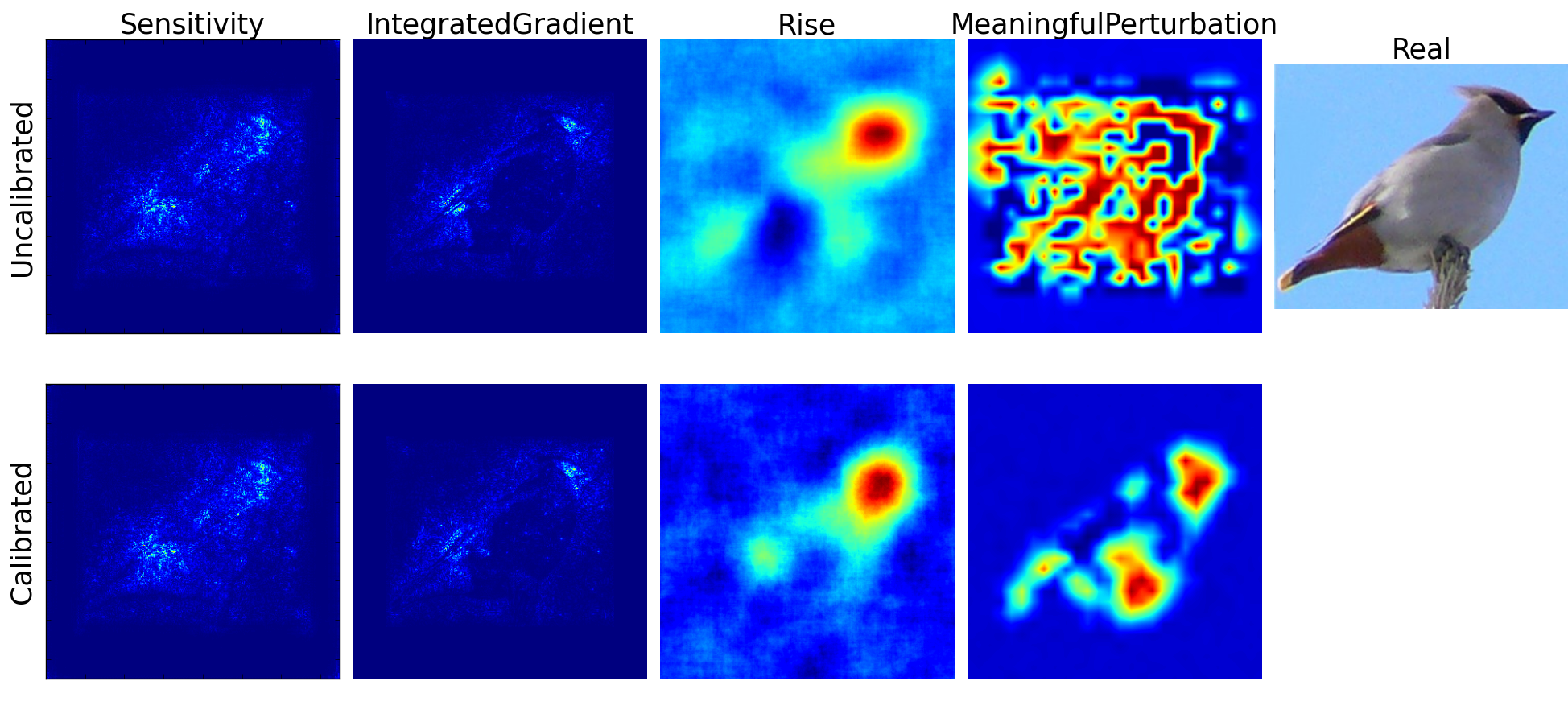
Trustworthy machine learning is driving a large number of ML community works in order to improve ML acceptance and adoption. The main aspect of trustworthy machine learning are the followings: fairness, uncertainty, robustness, explainability and formal guaranties. Each of these individual domains gains the ML community interest, visible by the number of related publications. However few works tackle the interconnection between these fields. In this paper we show a first link between uncertainty and explainability, by studying the relation between calibration and interpretation. As the calibration of a given model changes the way it scores samples, and interpretation approaches often rely on these scores, it seems safe to assume that the confidence-calibration of a model interacts with our ability to interpret such model. In this paper, we show, in the context of networks trained on image classification tasks, to what extent interpretations are sensitive to confidence-calibration. It leads us to suggest a simple practice to improve the interpretation outcomes: Calibrate to Interpret.
翻译:值得信赖的机器学习正在推动大量ML社区的工作,以改善对ML的接受和采用。值得信赖的机器学习的主要方面如下:公平、不确定性、稳健性、可解释性和正式保证。这些个别领域都赢得了ML社区的兴趣,从相关出版物的数量可见一斑。然而,处理这些领域之间相互联系的作品很少。在本文中,我们通过研究校准和解释之间的关系,显示了不确定性和可解释性之间的第一联系。由于对特定模型的校准改变了其评分方法,而解释方法往往依赖这些评分,因此,假设模型的信任校准与我们解释这种模型的能力相互作用似乎很安全。在本文中,我们在接受过图像分类任务培训的网络中显示了解释对信任校准的敏感程度。这使我们提出了改进解释结果的简单做法:Calibrate to Interpret。