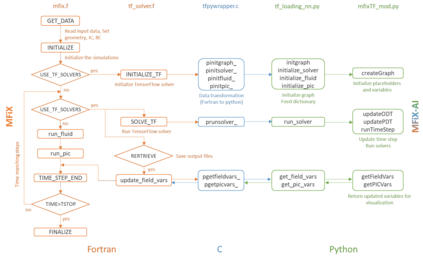
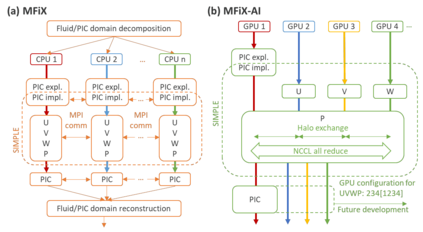
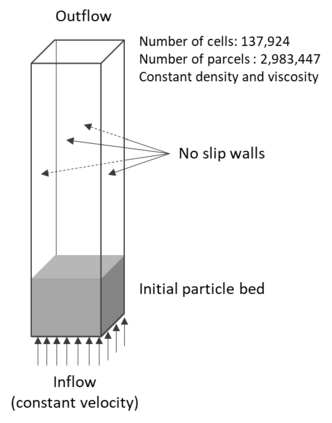
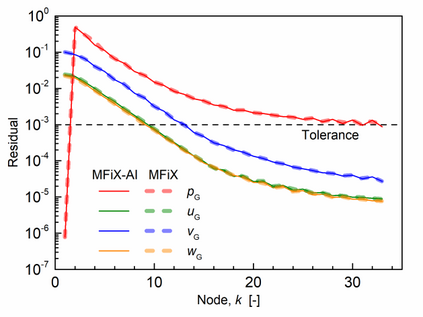
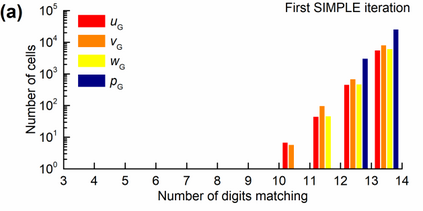
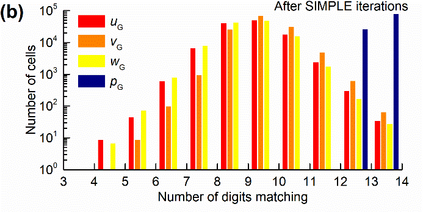
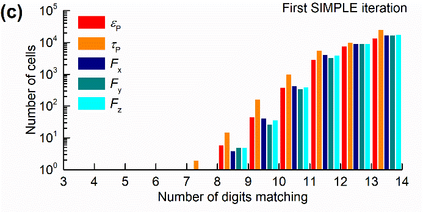
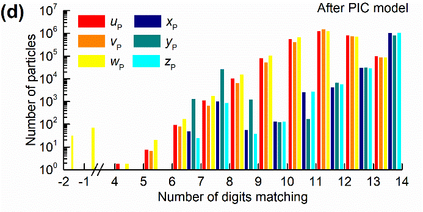
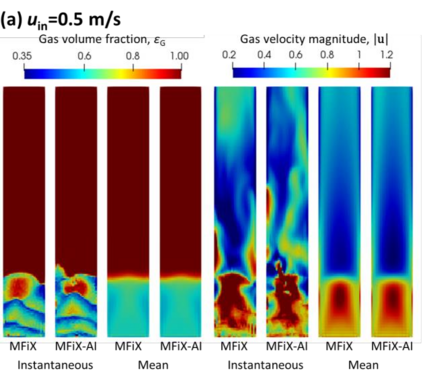
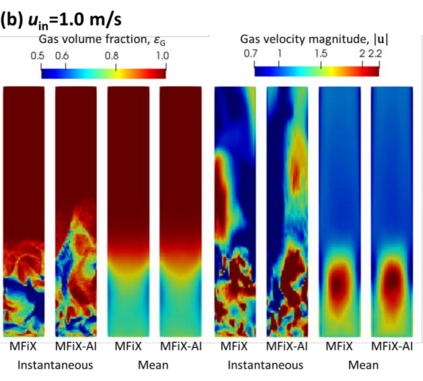
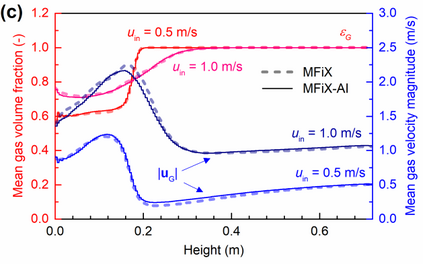
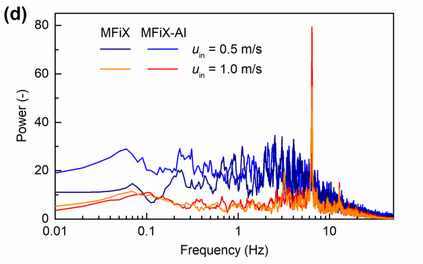
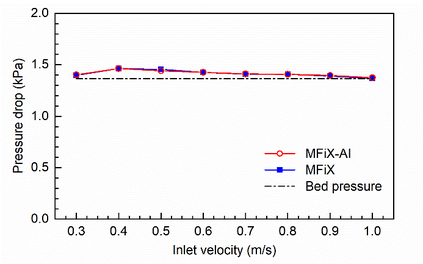
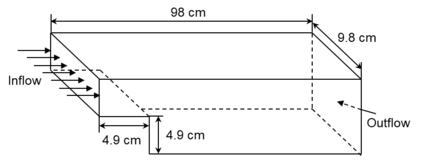
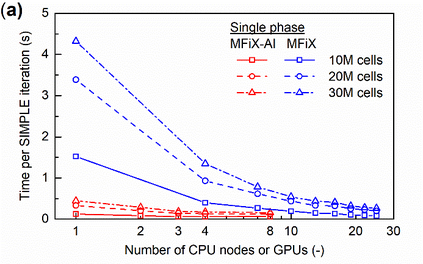
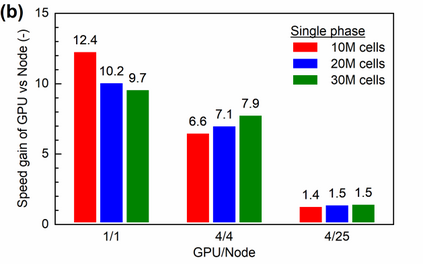
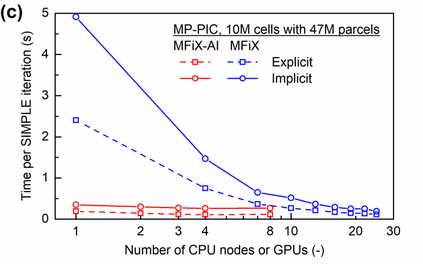
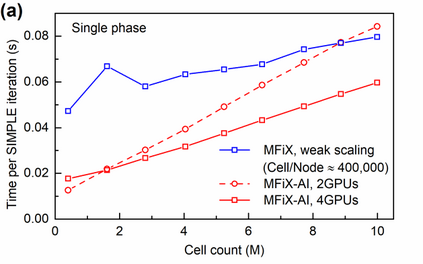
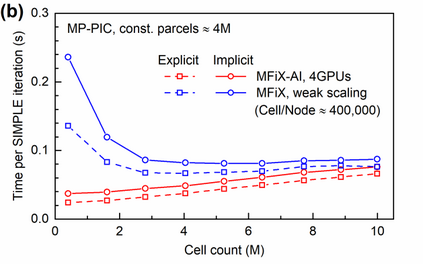
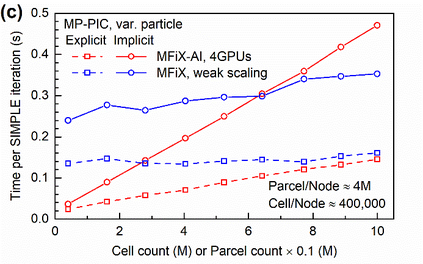
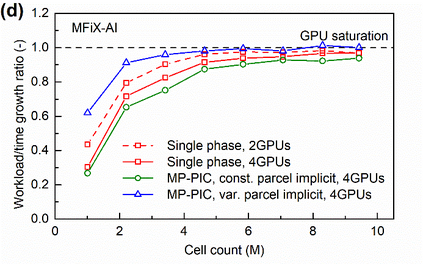
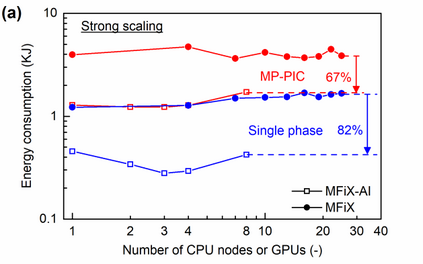
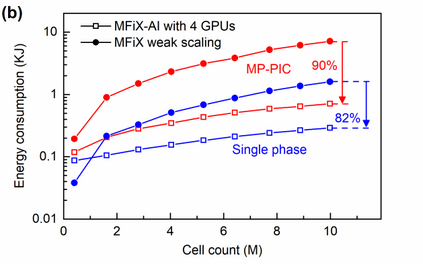
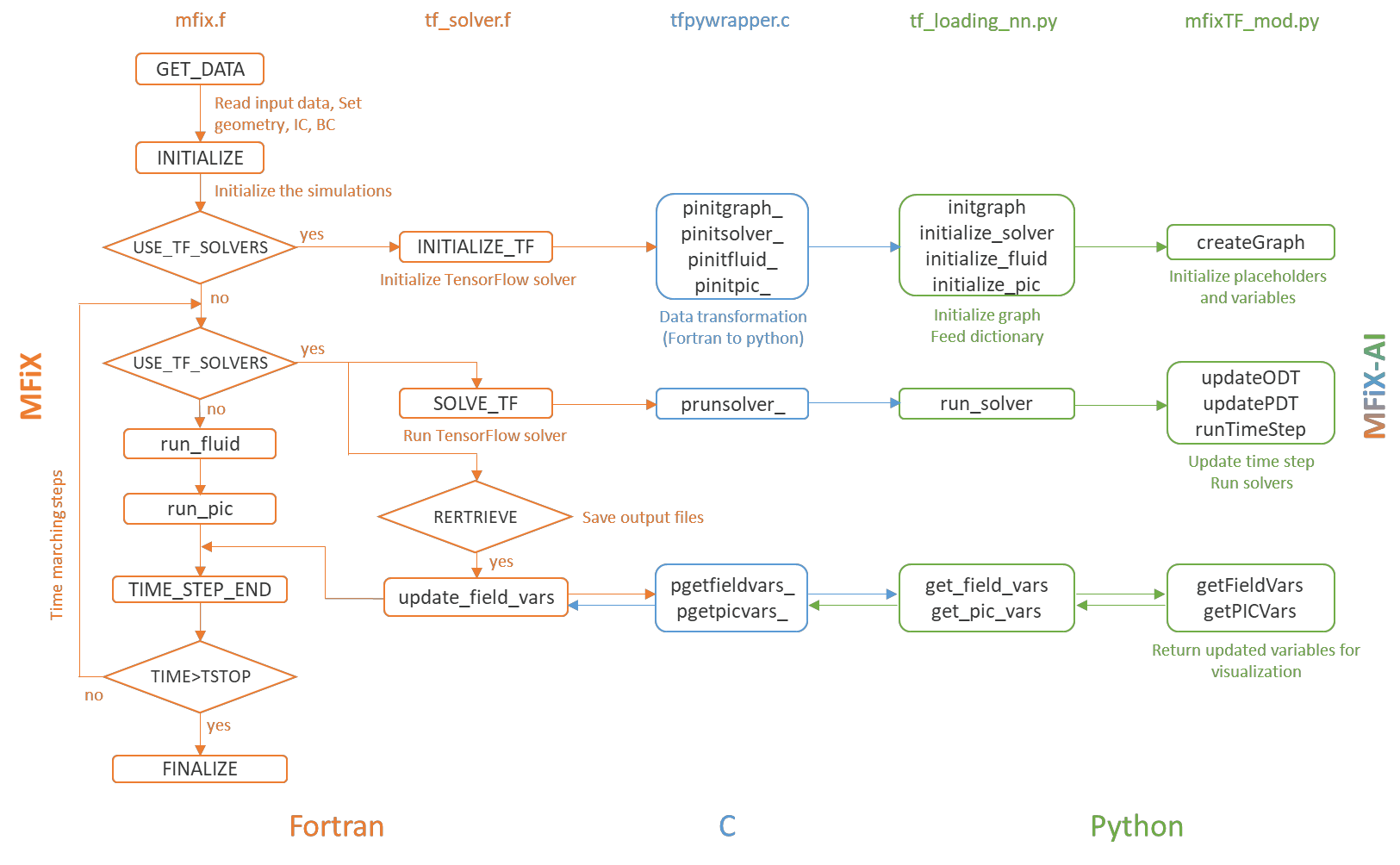
Manufacturers have been developing new graphics processing unit (GPU) nodes with large capacity, high bandwidth memory and very high bandwidth intra-node interconnects. This enables moving large amounts of data between GPUs on the same node at low cost. However, small packet bandwidths and latencies have not decreased which makes global dot products expensive. These characteristics favor a new kind of problem decomposition called "equation decomposition" rather than traditional domain decomposition. In this approach, each GPU is assigned one equation set to solve in parallel so that the frequent and expensive dot product synchronization points in traditional distributed linear solvers are eliminated. In exchange, the method involves infrequent movement of state variables over the high bandwidth, intra-node interconnects. To test this theory, our flagship code Multiphase Flow with Interphase eXchanges (MFiX) was ported to TensorFlow. This new product is known as MFiX-AI and can produce near identical results to the original version of MFiX with significant acceleration in multiphase particle-in-cell (MP-PIC) simulations. The performance of a single node with 4 NVIDIA A100s connected over NVLINK 2.0 was shown to be competitive to 1000 CPU cores (25 nodes) on the JOULE 2.0 supercomputer, leading to an energy savings of up to 90%. This is a substantial performance benefit for small- to intermediate-sized problems. This benefit is expected to grow as GPU nodes become more powerful. Further, MFiX-AI is poised to accept native artificial intelligence/machine learning models for further acceleration and development.
翻译:制造商一直在开发新的图形处理器( GPU) 节点, 其容量巨大, 带宽记忆高, 节点内部连接带宽甚高。 这使得在同一节点上的 GPU 之间能够以低成本移动大量数据。 但是, 小包带宽和延迟没有减少, 这使得全球点产品变得昂贵。 这些特征有利于一种名为“ quation decomposition” 而不是传统域分解的新型问题分解。 在这种方法中, 每个 GPU 都分配一个方程式, 以平行方式解决, 以便消除传统分布线性线性解决方案中经常和昂贵的点产品同步点。 在交换时, 方法涉及在同一节点上的 GPU 之间不经常移动大量数据。 然而, 我们的旗舰多阶段 与 eX change (MFixx) 连接起来, 这个新产品被称为 MFiX- AIX 和 mFIX 的原始版本几乎相同, 在多阶段微级粒子/ PIC( MP- PIC) 线性解中, 这个方法中, 这个方法的快速的模型的运行的运行运行性能将比高, 的运行的运行性性运行性运行性运行到高至高至高至高至高的模型, 这个模型的运行的运行的运行的运行性能性能的性能的运行性能将比为C.