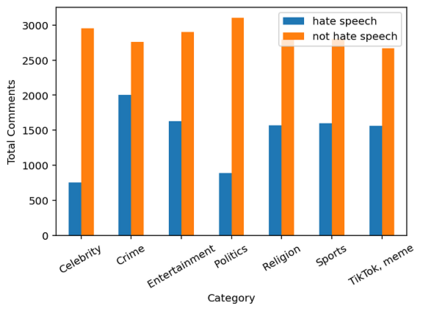
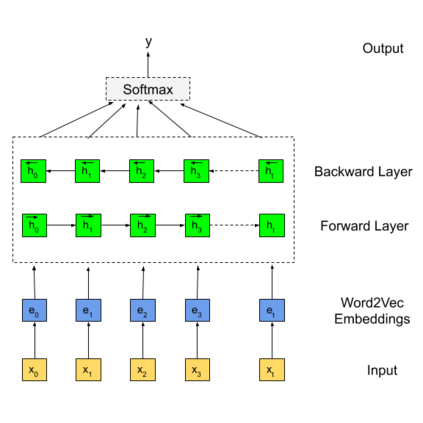
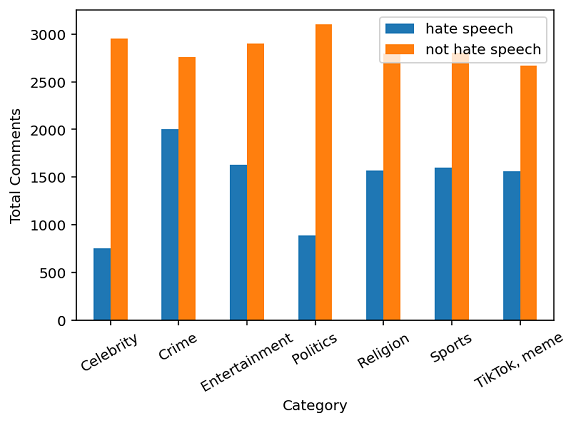
Social media sites such as YouTube and Facebook have become an integral part of everyone's life and in the last few years, hate speech in the social media comment section has increased rapidly. Detection of hate speech on social media websites faces a variety of challenges including small imbalanced data sets, the findings of an appropriate model and also the choice of feature analysis method. further more, this problem is more severe for the Bengali speaking community due to the lack of gold standard labelled datasets. This paper presents a new dataset of 30,000 user comments tagged by crowd sourcing and varified by experts. All the comments are collected from YouTube and Facebook comment section and classified into seven categories: sports, entertainment, religion, politics, crime, celebrity and TikTok & meme. A total of 50 annotators annotated each comment three times and the majority vote was taken as the final annotation. Nevertheless, we have conducted base line experiments and several deep learning models along with extensive pre-trained Bengali word embedding such as Word2Vec, FastText and BengFastText on this dataset to facilitate future research opportunities. The experiment illustrated that although all deep learning models performed well, SVM achieved the best result with 87.5% accuracy. Our core contribution is to make this benchmark dataset available and accessible to facilitate further research in the field of in the field of Bengali hate speech detection.
翻译:社会媒体网站(如YouTube和Facebook)已成为每个人生活的一个组成部分,过去几年来,社交媒体评论部分中的仇恨言论迅速增加。在社交媒体网站上发现仇恨言论面临各种挑战,包括小型的不平衡数据集、适当模式的发现和特征分析方法的选择。更严重的是,由于缺少标有标有金牌标签的数据集,这一问题对孟加拉语社区更为严重。本文展示了30,000个用户评论的新数据集,这些用户评论由众包标注,并被专家过滤。所有评论都从YouTube和Facebook评论部分收集,分类为七个类别:体育、娱乐、宗教、政治、犯罪、名人和TikTok & Meme。总共50个注解者,每次注解3次,多数选票作为最后注。然而,我们进行了基础线实验和若干深层次学习模型,以及大量经过事先训练的孟加拉语词,如Word2Vec、FastText和BengFastFastText, 以方便未来研究的机会。实验表明,尽管所有深度的模型都为87号核心的探测领域提供了最佳的精确性,但我们在Bengal 5 的实地进行了最精确的学习。